

آموزشsql
انواع page در پایگاه داده
آموزش پیشرفته SQL Server (جلسه اول) (Performance & tuning) - بررسی انواع page
بررسی انواع page، قسمتی از آموزش پیشرفته SQL Server است، پیشنهاد می شود قبل از مطالعه ی بررسی انواع page، قسمت های قبلی را مطالعه فرمایید.
انواع page
انواع Page در یک DataFile پایگاه داده در زیر آمده است:
- Data Page: اولین page (شماره صفر) در داخل یک DataFile می باشد. حساسیت این page بسیار بالاست به طوریکه اگر حتی یک بیت از آن به طور ناخواسته تغییر کند پایگاه داده از بین خواهد رفت. این نوع page برای ذخیره انواع داده به جز LOB ها استفاده می شود و تعداد زیادی از pageهای یک DataFile را تشکیل می دهد.
- PFS Page: دومین page در داخل یک DataFile (شماره یک) می باشد و برای نگهداری مقدار فضای خالی صفحات DataFile مورد استفاده قرار می گیرد. این نوع page برای مدیریت حداکثر 8080 page بکار برده می شود. مثال 2 این مورد را بهتر بیان می کند.
- GAM Page)Global Allocation Map): سومین page در DataFile (شماره دو) بوده وبرای ردیابی Extent های مورد استفاده (Uniform Exent) ها بکار می رود. این نوع page حداکثر می تواند 64000 Extent را مدیریت کند. روش کار آن بدین صورت است که هر Extent در آن دارای یک مدخل بوده و در صورتی که از آن استفاده شده باشد مقدار آن برابر با یک می شود.
- SGAM Page: چهارمین page در DataFile (شماره سه) بوده وبرای ردیابی Extent های مورد استفاده (Mixed Exent) ها بکار می رود. همه موارد ذکر شده در بالا برای این نوع page نیز صادق است.
- BCM Page: این نوع page برای ردیابی Extent هیی تغییر یافته بعد از آخرین Full Backup بکار می رود و بعد از گرفتن هر Full Backup مقدار آن reset می شود.
- DCM Page: این نوع page برای ردیابی Extent هیی تغییر یافته بعد از آخرین Bulk Operation بکار می رود و بعد از گرفتن هر Log Backup مقدار آن reset می شود.
- Index Page: به منظور ذخیره داده های مربوط به index ها بکار می روند. این page ها برای ذخیره سازی سطح ریشه و سطوح میانی B-Tree مربوط به index استفاده می شوند.

- Text/Image Page: این نوع page برای ذخیره و نگهداری LOB ها و Variable Length هایی که اندازه داده آنها از 8KB بیشتر است استفاده می شود. روشی که برای ذخیره این نوع فیلدها بکار می رود اینگونه است که در انتهای DataFile یک Text/Image Page ایجاد می شود و مقدار فیلد مربوطه در آن ذخیره می شود و در Data Page حاوی آن فیلد آدرس این صفحه به جای مقدار فیلد درج می گردد.
- IAM Page: برای ذخیره و نگهداری اطلاعات مربوط به Extent هایی که توسط جدول و یا index بکار برده شده اند بکار برده می شود. بنابراین SQL SERVER با کمک این نوع page تشخیص می دهد که چه page هایی در داخل یک DataFile مربوط به جدول و یا index ما می باشند. این نوع page در DataFile به ازای موارد زیر ایجاد می شود:

- به ازاء pageهای مربوط به داده های عادی
- به ازاء داشتن LOB در داخل جدول
- به ازاء Variable Length هایی که طول آنها از 8KB بیشتر شده و Row Overflow Data برای آن ستون در جدول رخ می دهد.
تذکر: هر سه نوع IAM Page ذکر شده بالا را با انجام مثال یک می توانید ببینید.
مثال عملی از بررسی انواع page
مثال 1: بررسی انواع IAM Page های ذکر شده به صورت عملی:
مرحله 1: برای مشاهده انواع ذکر شده IAM Page ابتدا جدولی با مشخصات زیر که دارای فیلدهای LOB می باشد، در یک پایگاه داده تستی ایجاد نمایید:
بررسی انواع page
CREATE TABLE IAM_Table
(
ID INT,
Data1 VARCHAR(3000),
Data2 VARCHAR(3000),
Data3 VARCHAR(3000),
LOBData TEXT
)
GOمرحله 2: در ادامه با استفاده از دستور زیر اطلاعاتی را که منجر به وقوع Row Overflow Data در جدول می شود درج نموده و با استفاده از دستور DBCC IND لیست page های موجود در جدول را بازیابی کنید:
بررسی انواع page
DECLARE @data1 VARCHAR(3000)
SET @data1 = REPLICATE('A',3000)
INSERT INTO IAM_Table VALUES (1,@data1,@data1,@data1,N'Test')
GODBCC IND('DB_Name','IAM_Table',1) WITH NO_INFOMSGS
GOهر سه نوع IAM Page را می توانید مطابق شکل زیر در خروجی ببینید:

مثال 2: بررسی PFS Page
با استفاده از دستور DBCC PAGE و درج مقدار 1 برای شماره page می توان به محتویات PFS Page دسترسی پیدا نمود :
بررسی انواع page
DBCC PAGE('table-name',1,1,3)WITH NO_INFOMSGSبا اجرای دستور بالا مطابق شکل زیر می بینیم که page شماره 32 دارای 50 درصد فضای خالی است.

در ادامه بحث بررسی انواع page خواهید دید...!
با خرید جلسه 5 از بسته آموزشی "افزایش کارایی پایگاه داده" موارد زیر را خواهید دید:
- با یک مثال عملی برای هر نوع page، انواع page نمایش داده خواهد شد.
- کاربردهای هر نوع از page ها در پایگاه داده بطور کامل شرح داده می شود.
- تاثیر عملیاتها و یا تعریف نوع داده اشتباه در DataFile بیان می گردد.
دسترسی به موارد آموزشی بالا در بسته خریداری شده
- شماره جلسه: 1
- نام فایل ویدئو: 06
- فرمت فایل: mp4.
نقطه شروع بحث بالا (بررسی انواع page در پایگاه داده) در ویدئو: 03:52
sql server چیست؟
در این فصل یاد می گیریم که sql server چیست و اینکه یک دیتابیس چیست و سپس توضیح می دهیم که با چه اشیائی می توان این دیتابیس ها را ایجاد نمود.
در این فصل شما فرا می گیرید که داده ها چگونه در یک دیتابیس ذخیره می شوند. همچنین در مورد اشیائی یاد می گیرد که به آنها ایندکس(index) گفته می شود. این ایندکس ها به sql server کمک می کنند تا به سرعت نتیجه ی حاصل از اجرای کوئری ها را برگرداند.
sql server چیست؟
sql server یک سیستم مدیریت دیتابیس رابطه ای است که به اختصار به آن RDBMS یا دیتابیس رابطه ای می گوییم. یک دیتابیس رابطه ای، بر اساس مدل رابطه ای(relational model)، داده ها را در جدول ها ذخیره می کند. شرکت مایکروسافت نسخه های مختلفی از sql server را منتشر کرده است. یکی از این نسخه ها، نسخه ی Express می باشد که مجانی است و می تواند در برنامه ها مورد استفاده قرار بگیرد و یا اینکه می تواند در زمینه ی آموزش sql server مورد استفاده قرار بگیرد. sql server نسخه های دیگری هم دارد که قیمت آنها بسیار گران می باشد(البته در ایران مجانی است). این نسخه ها عبارتند از:
- Standard
- Business Intelligence
- Enterprise
با استفاده از این نسخه ها می توان داده های بسیار زیادی را ذخیره کرد.
همچنین یک نسخه از sql server نیز وجود دارد که در بستر اینترنت قرار دارد و نام آن Microsoft Azure SQL Database است. یک نسخه ی دیگر نیز وجود دارد که نام آن Compact است و برای موبایل ها در نظر گرفته شده است.
جدول 2.1 خلاصه ای از نسخه های مختلف sql server را نشان می دهد. در اکثر نسخه های جدید sql server، قابلیتی به نام T-SQL قرار داده شده است.

دیتابیس های درون اینترنت(cloud)
نکته: cloud یا اَبر، در اصطلاح به معنی اینترنت می باشد.
امروزه محاسبات ابری(اینترنتی) دارای اهمیت بسیار زیادی هستند زیرا شرکت های بزرگ و مشتریان آنها، داده های خود را در اینترنت(cloud) نگه داری می کنند. بعنوان مثال، اکثر گوشی های هوشمند به کاربر امکان می دهند تا از داده های خود مثل عکس ها و کلیپ ها در اینترنت نسخه ی پشتیبان تهیه کنند.
شرکت مایکروسافت چندین دیتاسنتر در جهان دارد که حاوی هزاران سرور می باشند و این سرویس های اینترنتی را به ما ارائه می دهند. برخی از سرویس هایی که مایکروسافت به مشتریان خود ارائه می دهد عبارتند از:
- سرویس ایمیل(Outlook.com)
- سرویس ذخیره اطلاعات(OneDrive)
- سرویس Office
مایکروسافت همچنین برای استفاده های تجاری، سرویس Azure را ارائه می دهد. این سرویس به کمپانی ها امکان می دهد تا بدون آشنایی با انواع سخت افزارها، به راحتی به منابع مورد نیاز خود دست یابند و آنها را مدیریت کنند.
مایکروسافت می تواند به دو طریق، از دیتابیس شما در اینترنت(cloud) میزبانی کند. راه اول این است که مایکروسافت sql server را برای شما در ماشین مجازی Azure نصب کند؛ به طوری که سرور شما توسط مایکروسافت میزبانی شود. و یا اینکه شما sql server را در سرور دیتاسنتر خود نصب کنید. راه دوم این است که مایکروسافت یک دیتابیس Microsoft Azure SQL را ایجاد کنید. ( در این روش شما تنها می توانید دیتابیس ها را مدیریت کنید).
فرق زیادی بین روش اول و دوم وجود ندارد، به جز اینکه برخی دستورات مدیریتی و برخی از ویژگی های پیشرفته را نمی توانید انجام دهید. اما غالبا در هر دو روش، زبان T-SQL یکسان است.
یکی از مزیت های Microsoft Azure SQL Database این است که مایکروسافت قادر است تا آپدیت ها را خودش نصب کند. در فصل 17 در مورد Microsoft Azure SQL Database مطالب بیشتری را خواهید آموخت.
سرویس یا اپلیکیشن
sql server یک سرویس است و تنها یک اپلیکیشن نمی باشد. با اینکه شما می توانید برخی از نسخه های sql server را بر روی یک ایستگاه کاری(workstation) نصب کنید، اما sql server بر روی یک سرور اختصاصی اجرا می شود و هنگامی که این سرور شروع به کار می کند، اجرا خواهد شد. به عبارت دیگر، هیچ احتیاجی به این نیست که به طور دستی sql server را راه اندازی(start) کنیم.
برای اینکه به طور عملی، از کار افتادگی سیستم های حیاتی را کاهش دهیم و یا از بین ببریم، sql server دارای ویژگی هایی است که باعث می شود به میزان زیادی در دسترس باشد. که عبارتند از:
- clustering
- log shipping
- database mirroring
- Availability Groups
فرض کنید که شما یک وب سایت فروشگاهی دارید. شما انتظار دارید که این وب سایت شب و روز در دسترس باشد. برای انجام این کار، سرور دیتابیس شما، که احتمالا یک نمونه از sql server است، باید همواره در حال اجرا باشد و به درستی کار کند. حتی در زمان های ضروری مثال زمان تعمیر و نصب وصله های امنیتی، مدیران sql server باید تلاش کنند که زمان از کار افتادگی را به حداقل برسانند.
sql server ویژگی های فراوانی دارد و یک مجموعه ی کامل از هوش تجاری(business intelligence) و ابزارهای مدیریتی موثر(impressive management tools) و ویژگی تکرار داده ها در سطح بالا(sophisticated data replication features) را به همراه دیگر ویژگی ها، ارائه می دهد.
sql server، دارای یک رابط ثبت داده ها(data-entry interface) برای کاربران عادی نیست و راهی برای ایجاد یک وب سایت یا برنامه ی ویندوز در اختیار شما قرار نمی دهد. برای انجام این کارها، باید از یک زبان برنامه نویسی مثل visualBasic.NET یا #C استفاده کنید.
فراخوانی sql server از طریق T-SQL می تواند از داخل اپلیکیشن شما یا از طریق یک وب سرویس با رده ی متوسط صورت بگیرد. بدون در نظر گرفتن معماری اپلیکیشن شما، ممکن است به T-SQL احتیاج پیدا کنید.
sql server یک ابزار گزارش دهی جالب به نام Reporting Services دارد که بخشی از مجموعه ی هوش تجاری(business intelligence suite) می باشد. در صورتی که sql server این ابزار را نداشته باشد، شما مجبورید از یک زبان برنامه نویسی دیگر برای ایجاد یک رابط کاربری در بیرون از ابزارهای مدیریتی استفاده کنید.
عکس 2.1 معماری یک اپلیکیشن وب معمولی را نشان می دهد. همان طور که در این تصویر مشاهده می کنید، وب سرور، داده ها را از سرور دیتابیس درخواست می کند. کلاینت ها با وب سرور ارتباط برقرار می کنند.
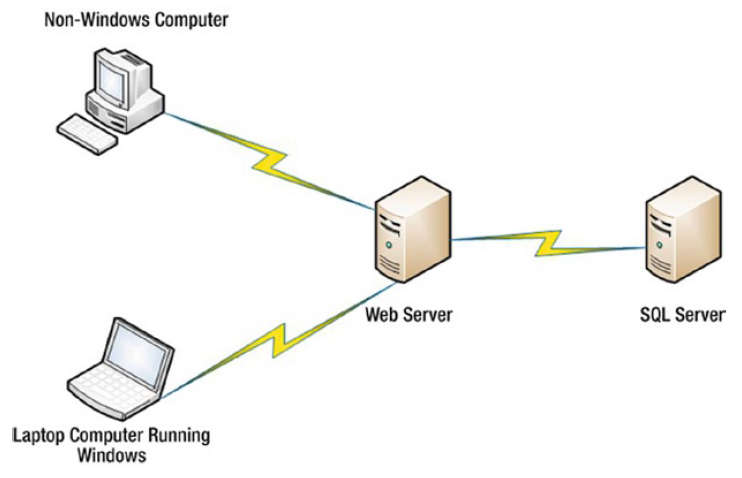
دیتابیس بعنوان یک شیء دربرگیرنده(container)
یک دیتابیس در sql server، در اصل یک شیء دربردارنده(container) است که انواع مختلفی از اشیاء و داده ها را به شکل منظم نگهداری می کند. به طور کلی از یک دیتابیس برای یک اپلیکیشن یا هدف خاص استفاده می شود. اما این یک قانون حتمی نیست.
بعنوان مثال، برخی از سیستم ها از یک دیتابیس برای تمام کارهای خود استفاده می کنند. از طرف دیگر، یک اپلیکیشن قادر است تا به بیش از یک دیتابیس دسترسی داشته باشد.
استودیوی مدیریت sql server را اجرا کنید البته در صورتی که قبلا اجرا نشده باشد و سپس به sql server با استفاده از اطلاعات هنگام نصب آن، متصل شوید. حالا پوشه ی Databases را باز کنید تا دیتابیس های نصب شده بر روی sql server را مشاهده کنید. حالا طبق عکس 2.2 شما قادر خواهید بود تا دیتابیس AdventureWorks را مشاهده کنید.

در داخل یک دیتابیس، چندین شیء وجود دارند اما تنها یک نوع از این اشیاء یعنی جدول ها قادر هستند تا داده هایی که ما در مورد آنها فکر می کنیم را در خود ذخیره کنند. علاوه بر جدول ها، یک دیتابیس قادر است تا اشیاء دیگری را نیز در خود نگهداری کند. لیست این اشیاء در جدول 2.2 آورده شده است.
نوع شیء توضیحات Views A stored query definition that can be used to simplify writing T-SQL statements or to control
security to data.Stored procedures A stored T-SQL script that can include queries, data definition statements (DDL) that create
or modify objects, and programming logic. Stored procedures can return tabular data results.User-defined
functionsA user-defined function is similar to a stored procedure but with several differences. They
can return tabular data or a single value, but they cannot affect anything outside the function.Indexes A structured that assists the database engine when locating rows. Constraints Rules controlling the behavior of the table and columns and the data that can be stored in a
column.Triggers A trigger is a special type of stored procedure that fires when something happens in the
database such as a row is inserted or an object is created.Types Each column in a database has rules governing what type of data the column can contain.
It is possible to create custom types to help organize the database.Rules and defaults These features are no longer recommended and are only available for backward compatibility. Plan guides This is an advanced feature used to override SQL Server’s behavior for a particular query.
It is well beyond the scope of this book.Sequences Sequences are containers holding incrementing numbers. Synonyms Synonyms are nicknames or aliases for database objects. Assemblies Assemblies are references to database objects created in a .Net language.
This functionality is called common language runtime (CLR) integration.بررسی فایل های sql server
یک دیتابیس در sql server حداقل باید شامل دو فایل باشد: یکی فایل های داده است که پسوند پیشفرض آنها mdf. می باشد و دیگری فایل های log است که پسوند پیشفرض آنها ldf. می باشد. اگر فایل های داده ی اضافی هم مورد استفاده قرار بگیرند، معمولا پسوند آنها ndf. می باشد.
به طور تکنیکی می توان گفت که فایل ها با پسوند mdf و ldf و ndf می توانند هر نوع پسوند دلخواهی داشته باشند، اما توصیه نمی شود که آنها را از حالت پیش فرض تغییر دهید.
فایل های داده را می توان در چندین گروه فایل( file groups) سازمان دهی کرد.
گروه های فایل(File groups) برای بک آپ گرفتن از بخش هایی از دیتابیس در یک زمان،، مناسب هستند. و یا اینکه برای ذخیره ی داده ها در درایو های مختلف به منظور افزایش کارایی مناسب هستند.
این تنها یک مقدمه ی کوتاه در مورد فایل ها و گروه های فایل(file groups) است.
فایل ها و گروه های فایل دیگری نیز وجود دارند که فراتر از سطح این کتاب هستند و در اینجا به آموزش آنها نخواهیم پرداخت.
فایل log در sql server تراکنش ها یا تغییرات فایل ها را در خود ذخیره سازی می کند تا بتوان داده ها را پیگیری نمود.
مدیران دیتابیس ها قادر هستند تا بکاپ های مکرری را از فایل های log بگیرند تا به دیتابیس امکان دهند تا در صورت خرابی داده ها یا خرابی دیسک یا دیگر اتفاقات، عمل احیای مجدد(restore) به زمان های قبلی را انجام دهند.
برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
wildcard چیست؟
wildcard ها می توانند هنگام جستجوی داده از یک پایگاه داده مورد استفاده قرار گیرند.
Wildcardها یا کاراکترهای جایگزین در SQL
Wildcardها می توانند جانشین یک یا چند کاراکتر برای جستجوی داده در یک پایگاه داده شوند.
Wildcardها باید به همراه عملگر LIKE استفاده شوند.
Wildcardهای زیر در SQL می توانند استفاده شوند:
Wildcard توضیحات % جانشینی برای صفر یا چند کاراکتر _ جانشینی برای دقیقا یک کاراکتر [charlist] کاراکترهای نوشته شده در براکت یا [^charlist] [!charlist]
به غیر از کاراکترهای نوشته شده در براکت
مثال Wildcardها
در جدول Persons
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger کاربرد %
می خواهیم افرادی را انتخاب کنیم که در شهری زندگی می کنند که با sa شروع می شود.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE City LIKE 'sa%'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes حال می خواهیم افرادی را انتخاب کنیم که در شهری زندگی می کنند که نام آن شهر حاوی nes می باشد.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE City LIKE '%nes%'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes کاربرد _ (زیر خط)
می خواهیم افرادی را انتخاب کنیم که نام کوچک (first name) آنها با هر کاراکتری شروع شود و در ادامه حروف la آمده باشد.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE FirstName LIKE '_la'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes حال می خواهیم افرادی را انتخاب کنیم که نام خانوادگی (last name) آنها با s شروع می شود و بعد از آن یک کاراکتر باشد و در ادامه end باشد و بعد یک کاراکتر باشد و در ادامه on باشد.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE LastName LIKE 'S_end_on'جدول نتایج به شکل زیر خواهد شد:
P_Id LastName FirstName Address City 2 Svendson Tove Borgvn 23 Sandnes کاربرد [آرایه ای از کاراکترها]
می خواهیم از جدول persons افرادی را انتخاب کنیم که نام خانوادگی آنها با "b" یا "s" یا "p" شروع می شود.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE LastName LIKE '[bsp]%'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger می خواهیم از جدول persons افرادی را انتخاب کنیم که نام خانوادگی آنها با "b" یا "s" یا "p" شروع نشود.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE LastName LIKE '[!bsp]%'جدول نتایج به شکل زیر خواهد شد:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
انوع داده در SQL
انواع داده ها (Data type) و دامنه آن ها در Microsoft Access ,MySQL و SQL Server
انواع داده ها در Microsoft Access
نوع داده توضیحات فضا Text متن یا ترکیب متن و اعداد، حداکثر 255 کاراکتر
Memo متن های طولانی، حدکثر 65,536 کاراکتر
توجه: فیلدهای از نوع Memo را نمی توان مرتب (sort) کرد، اما قابل جستجو هستند
Byte اجازه می دهد هرعددی از 0 تا 255 را وارد کرد
1 byte Integer اجازه می دهد هرعددی بین 32767 تا 32768- وارد شود
2 bytes Long اجازه می دهد هرعددی بین 2,147,483,647 تا 2,147,483,648- وارد شود
4 bytes Single اعداد اعشاری با دقت واحد
4 bytes Double اعداد اعشاری با دقت مضاعف
8 bytes Currency از این نوع داده ها برای نگهداری مقادیر پولی یا ارزی استفاده می شود. اکسس تمامی مقادیر پولی/ارزی را با ۱۵ رقم در سمت چپ و چهار رقم در سمت راست نقطه اعشار نگه می دارد, لذا می توانید اعداد با دقت بالا را در فیلدهای پولی نگه دارید
توجه: می توانید کشوری که ارز مورد نظرتان در آن استفاده می شود را انتخاب نمایید8 bytes AutoNumber وقتی که فیلدی را را از نوع داده Auto number تعریف می کنید، با هر رکوردی که به جدول اضافه شود اکسس به طور خودکار عددی را در این فیلد نگه می دارد
4 bytes Date/Time برای نگهداری داده های از نوع تاریخ و زمان استفاده می شود
8 bytes Yes/No فیلدی که از نوع Yes/No تعریف می شود به ازای Yes عدد ۱- و به ازای No عدد ۰ را دارا می شود. با استفاده از بخش Filed Properties در پنجره مذکور می توانید بسته به دلیل استفاده از فیلد, یکی از سه حالت Yes/No, True/False (درست یا غلط) یا On/Off (روشن و خاموش) را به کار ببرید.
توجه: مقدار NULL را نمی پذیرد1 bit Ole Object OLE مخفف Object Linking and Embedding (اتصال و نشاندن شی) است.
فیلدهای OLE برای نگه داری اشیایی از قبیل عکس, تصاویر ویدیوئی و صدا مناسب است.up to 1GB Hyperlink شامل لینک هایی به دیگر فایل ها یا صفحات وب است
Lookup Wizard هنگام تعریف این نوع داده، یک لیست از گزینه های انتخابی را مشخص می کنید و هنگام ورود اطلاعات یک لیست کشویی نمایش داده خواهد شد
4 bytes انواع داده ها در MySQL
در MySQL سه نوع اصلی داده وجود دارد: نوع متنی، نوع عددی و نوع تارخ/زمان
داده های متنی
نوع داده توضیحات CHAR(size) رشته ای با طول ثابت (می تواند شامل حروف، اعداد و کاراکترهای خاص باشد)
طول رشته در پرانتر مشخص می شود و حداکثر 255 کاراکتر استVARCHAR(size) رشته ای با طول متغیر (می تواند شامل حروف، اعداد و کاراکترهای خاص باشد)
حداکثر طول رشته در پرانتز مشخص می شود و حداکثر 255 کاراکتر است
توجه: اگر رشته ای با طول بیش از 255 کاراکتر را در آن قرار دهید، به نوع TEXT تبدیل خواهد شد
TINYTEXT رشته ای با طول حداکثر 255 کاراکتر
TEXT رشته ای با طول حداکثر 65,535 کاراکتر
BLOB داده باینتری با طول حداکثر 65,535 بایت (Binary Large OBject)
MEDIUMTEXT رشته ای با طول حداکثر 16,777,215 کاراکتر
MEDIUMBLOB داده باینتری با طول حداکثر 16,777,215 بایت (Binary Large OBject)
LONGTEXT رشته ای با طول حداکثر 4,294,967,295 کاراکتر
LONGBLOB داده باینتری با طول حداکثر 4,294,967,295 بایت (Binary Large OBject)
ENUM(x,y,z,etc.) فقط یکی از مقادیری که در پرانتز لیست شده است، اجازه ورود دارد. می توانید حداکثر 65535 کاراکتر در ENUM لیست کنید
اگر مقداری که در لیست وجود ندارد، درج شود، یک blank یا فضای خالی بجای آن در نظر گرفته می شود
توجه: مقادیر به ترتیبی که شما وارد کرده اید، مرتب می شوندSET مانند ENUM است با این تفاوت که، حداکثر 64 آیتم می توانید لیست کنید و همچنین بیشتر از یک انتخاب دارید
داده های عددی
نوع داده توضیحات فضا TINYINT(size) محدوده اعداد مجاز به صورت علامت دار: 128- تا 127
محدوده اعداد مجاز به صورت بدون علامت: 0 تا 2551 byte
SMALLINT(size) محدوده اعداد مجاز به صورت علامت دار: 32768- تا 32767
محدوده اعداد مجاز به صورت بدون علامت: 0 تا 655352 byte
MEDIUMINT(size) محدوده اعداد مجاز به صورت علامت دار: 8388608- تا 8388607
محدوده اعداد مجاز به صورت بدون علامت: 0 تا 167772153 byte
INT(size) محدوده اعداد مجاز به صورت علامت دار: 2147483648- تا 2147483647
محدوده اعداد مجاز به صورت بدون علامت: 0 تا 42949672954 byte
BIGINT(size) محدوده اعداد مجاز به صورت علامت دار: 9223372036854775808- تا 9223372036854775807
محدوده اعداد مجاز به صورت بدون علامت: 0 تا 184467440737095516158 byte
FLOAT(size,d) از این دو نوع داده برای ذخیره اعداد اعشاری با ممیز شناور استفاده می شود
پارامتر size حداکثر تعداد ارقام و پارمتر d حداکثر تعداد ارقام سمت راست ممیز اعشار را مشخص می کند
پارامتر size نشان دهنده 4 byteی یا 8 byteی بودن فیلد است. اگر بین ا تا 24 باشد، 4 byteی است و اگر بین 25 تا 53 باشد، 8 byteی است4 یا 8 byte DOUBLE(size,d) از این دو نوع داده برای ذخیره اعداد اعشاری با ممیز شناور استفاده می شود
پارامتر size حداکثر تعداد ارقام و پارمتر d حداکثر تعداد ارقام سمت راست ممیز اعشار را مشخص می کند
8 byte
DECIMAL(size,d) از این نوع داده برای نگهداری اعداد اعشاری با ممیز ثابت استفاده می شود. این نوع داده برای هر ۹ رقم ، ۴ بایت فضا اشغال می کند
پارامتر size حداکثر تعداد ارقام و پارمتر d حداکثر تعداد ارقام سمت راست ممیز اعشار را مشخص می کند- اگر هنگام تعریف فیلد از کلمه کلیدی UNSIGNED استفاده کنیم میتوانیم مقادیر بدون علامت را درون فیلد بریزیم، ولی بطور پشفرض فیلد ها مقادیر علامت دار (SIGNED) را می پذیرند.
- میتوان تعداد ارقامی که به نوع دادهٔ Integer نسبت داده می شود را محدود نمود، به عنوان مثال: (INT(5 یعنی فیلدی از جنس INT که 5 رقم را در خود جای می دهد.
- وقتی از کلمه کلیدی ZEROFILL استفاده می کنیم، اگر مقدار نسبت داده شده به فیلد از تعداد ارقام مشخص شده کمتر باشد، با اضافه کردن 0 به سمت چپ عدد، آن مقدار را هم اندازه تعداد ارقام مشخص شده می کند.
داده های تاریخ/زمان
نوع داده توضیحات فضا DATE() این نوع داده برای نگهداری تاریخ (بدون ساعت)، با غالب 'YYYY-MM-DD' استفاده می شود
توجه: محدوده تاریخی بصورت '01-01-1000' تا '31-12-9999' می باشد3 byte
DATETIME() این نوع داده برای نگهداری زمان (هم تاریخ و هم ساعت بصورت تفکیک شده و بدون توجه به منطقه زمانی)، با غالب 'YYYY-MM-DD HH:MM:SS' استفاده می شود
توجه:محدوده زمانی بصورت '00:00:00 01-01-1000' تا '23:59:59 31-12-9999' می باشد.8 byte
TIMESTAMP() هر زمان سطری ایجاد یا تغییر داده می شود، یک عدد یکتا بصورت اتوکاتیک در این فیلد ذخیره می شود. داده timestamp وابسته به ساعت داخلی سیستم می باشد و با زمان واقعی مطابقت ندارد. هر جدولی ممکن است یک timestamp متفاوت داشته باشد.
به عبارت دیگر در این فیلد ۸ بایتی، تایم لحظهای اجرای دستور نگهداری میشود و کاربرد آن کنترل بروزرسانی همزمان (Concurrency) اطلاعات توسط چند کاربر است. البته در تعداد رکوردهای پایین به کار نمیآید و بیشتر زمانی مورد نیاز است که تعداد رکوردها خیلی زیاد باشد مثلاً ۱۰۰ میلیون رکورد!
توجه: محدوده زمانی بصورت '00:00:00 01-01-1000' UTC تا '23:59:59 31-12-9999' UTC می باشد. یعنی هنگام ذخیره سازی زمان ، آن را از زمان محلی (Time Zone) سیستم به زمان UTC (گیرینویچ) تبدیل می کند و هنگام بازیابی ، آنرا از UTC به زمان محلی سیستم تبدیل می کند.
4 byte
TIME() این نوع داده برای نگهداری زمان (فقط ساعت ، بدون تاریخ)، با غالب 'HH:MM:SS' یا 'HHH:MM:SS' استفاده می شود
توجه: محدوده ساعتی بصورت '838:59:59-' تا '838:59:59' می باشد. علت پذیرش مقدار منفی در این نوع داده این است که می توان از این نوع داده برای ذخیره اختلاف دو زمان استفاده کرد3 byte
YEAR() ذخیره سال به فرمت: دو رقمی یا چهار رقمی
توجه: مقادیر چهار رقمی: از 1901 تا 2155 و مقادیر دو رقمی: از 70 تا 69 که نماینده 1970 و 2069 است1 byte
انواع داده ها در SQL Server
داده های متنی
نوع داده توضیحات فضا char(n) رشته ای با طول ثابت، حداکثر 8000 کاراکتر
مصرف فضای ابن نوع وابسته به تعداد کاراکترهای آن است هر کاراکتر یک بایت اشغال می کندn می تواند عددی بین 1 تا 8000 باشد
توجه: اگر 5=n باشد و 2 کاراکتر وارد کنید، 3 کاراکتر باقی مانده با Space پر می شود
مزیت این نوع داده در جستجوی سریع آن است
n varchar(n) رشته ای با طول متغیر، حداکثر 8000 کاراکتر
از این نوع داده زمانی استفاده می کنیم که میزان فضایی که داده ها اشغال می کنند بسیار متغیر باشدتوجه: اگر 5=n باشد و 2 کاراکتر وارد کنید، فقط به اندازه 2 کاراکتر فضا اشغال می شود (3 کاراکتر باقی مانده در نظر گرفته نمی شود)
مزیت این نوع داده در میزان فضای استفاده شده است
varchar(max) رشته ای با طول متغیر، حداکثر 1,073,741,824 کاراکتر
به جای n در مورد قبلی می توان از عبارت max استفاده کرد تا حداکثر فضای امکان پذیر در دسترس باشد
text رشته کاراکتر با طول متغیر، حداکثر 2GB داده متنی
داده های متنی Unicode
نوع داده توضیحات فضا nchar(n) داده Unicode با طول ثابت، حداکثر 4,000 کاراکتر
میزان مصرف این نوع داده دو بایت به ازای هر کاراکتر است. بخاطر این موضوع، n باید بین یک تا چهار هزار تعیین شود
nvarchar(n) داده Unicode با طول متغیر، حداکثر 4,000 کاراکتر
nvarchar(max) داده Unicode با طول متغیر، حداکثر 536,870,912 کاراکتر
ntext داده Unicode با طول متغیر، حداکثر 2GB داده متنی
داده های Binary
نوع داده توضیحات فضا bit 0، 1 یا NULL
binary(n) داده باینری با طول ثابت حداکثر 8000 بایت
varbinary(n) داده باینری با طول متغیر حداکثر 8000 بایت
varbinary(max) داده باینری با طول متغیر حداکثر 2GB
image داده باینری با طول متغیر حداکثر 2GB
داده های عددی
نوع داده توضیحات فضا tinyint اعداد صحیح بین 0 تا 255
1 byte smallint اعداد صحیح بین 32,767 تا 32,768-
2 bytes int اعداد صحیح بین 2,147,483,647 تا 2,147,483,648 -
معادل از منفی 231تا 231 منهای یک است4 bytes bigint اعداد صحیح بین 9,223,372,036,854,775,807 تا 9,223,372,036,854,775,808-
که معادل از منفی 263 تا 263منهای یک است
8 bytes decimal(p,s) اعداد با مقیاس (scale) و دقت (precision) ثابت
از منفی 1038 بعلاوه یک تا 1038منهای یک
پارامتر p ماکزیمم تعداد ارقام یک عدد را نشان می دهد (شامل هم ارقامی که سمت راست علامت اعشار می آیند و هم ارقامی که سمت چپ علامت اعشار می آیند) پارامتر p باید مقداری بین صفر تا 38 باشد. مقدار پیش فرض 18 می باشد.
پارامتر s ماکزیمم تعداد ارقامی که سمت راست علامت اعشار می آید را نشان می دهد. پارامتر s باید عددی بین صفر تا p باشد. مقدار پیش فرض عدد صفر است5-17 bytes numeric(p,s) اعداد با مقیاس (scale) و دقت (precision) ثابت
از منفی 1038 بعلاوه یک تا 1038منهای یک
پارامتر p ماکزیمم تعداد ارقام یک عدد را نشان می دهد (شامل هم ارقامی که سمت راست علامت اعشار می آیند و هم ارقامی که سمت چپ علامت اعشار می آیند) پارامتر p باید مقداری بین صفر تا 38 باشد. مقدار پیش فرض 18 می باشد.
پارامتر s ماکزیمم تعداد ارقامی که سمت راست علامت اعشار می آید را نشان می دهد. پارامتر s باید عددی بین صفر تا p باشد. مقدار پیش فرض عدد صفر است5-17 bytes smallmoney داده های ارزی بین 214,748.3648- تا214,748.3647
4 bytes money داده های ارزی بین 922,337,203,685,477.5808- تا 922,337,203,685,477.5807
8 bytes float(n) برای نگهداری اعداد غیر صحیح با تعداد ارقام اعشار متغیر و یا تخمـینـی استفاده میشود (from -1.79E + 308 to 1.79E + 308)
پارامتر n نشان دهنده 4 byteی یا 8 byteی بودن فیلد است. اگر بین ا تا 24 باشد فیلد، 4 byteی است و اگر بین 25 تا 53 باشد فیلد، 8 byteی است. مقدار پیش فرض عدد 53 است.4 یا 8 bytes real برای نگهداری اعداد غیر صحیح با تعداد ارقام اعشار متغیر و یا تخمـینـی استفاده میشود (from -3.40E + 38 to 3.40E + 38)
4 bytes داده های تاریخ و زمان
این نوع فیلدها برای نگهداری تاریخ میلادی و ساعت استفاده میشود و برای تاریخ شمسی کاربردی ندارد.
نوع داده توضیحات فضا datetime از تاریخ اول January سال 1753 تا سی ویکم December سال 9999 با دقت 3.33 میلی ثانیه
8 bytes datetime2 از تاریخ اول January سال 0001 (01/01/0001) تا سی ویکم December سال 9999 (31/12/9999) با دقت 100 نانو ثانیه
6-8 bytes smalldatetime از تاریخ اول January سال 1900 تا ششم June سال 2079 با دقت یک دقیقه
4 bytes date فقط تاریخ را ذخیره می کند. از تاریخ اول January سال 0001 (01/01/0001) تا سی ویکم December سال 9999(31/12/9999)
3 bytes time فقط زمان را ذخیره می کند با دقت 100 نانو ثانیه
3-5 bytes datetimeoffset مشابه datetime2 می باشد به علاوه timeoffset را ذخیره می کند
8-10 bytes timestamp هر زمان سطری ایجاد یا تغییر داده می شود، یک عدد یکتا ذخیره می شود. داده timestamp وابسته به ساعت داخلی سیستم می باشد و با زمان واقعی مطابقت ندارد. هر جدولی ممکن است یک timestamp متفاوت داشته باشد.
به عبارت دیگر در این فیلد ۸ بایتی، تایم لحظهای اجرای دستور نگهداری میشود و کاربرد آن کنترل بروزرسانی همزمان (Concurrency) اطلاعات توسط چند کاربر است. البته در تعداد رکوردهای پایین به کار نمیآید و بیشتر زمانی مورد نیاز است که تعداد رکوردها خیلی زیاد باشد مثلاً ۱۰۰ میلیون رکورد!
انواع داده ای دیگر
نوع داده توضیحات sql_variant این نوع فیلد، به جز داده های text, ntext, timestamp برای نگهداری انواع داده های دیگر استفاده میشود و نوع آن با توجه به اولین مقداری که در آن قرار میگیرد تعیین خواهد شد. (حداکثر 8000 بایت) چون نوع و حجم فیلد مشخص نیست، لذا تنها یک اشارهگر ۱۶ بایتی در آن قرار گرفته و داده اصلی در فایل جداگانه نگهداری میشود. استفاده از این نوع فیلد، توصیه نمیگردد.
uniqueidentifier این فیلد ۱۶ بایتی، به ما کدی Unique یا یکتا میدهد که به اصطلاح GUID میگویند. یکی از کاربردهای آن در Replication است.
xml داده هایی با فرمت XML را ذخیره می کند. (حداکثر 2GB)
این فیلد بیشتر برای انتقال اطلاعات و دستورات تحت web استفاده میشود و شامل انواع MetaData های مختلف است. این فیلد در SQL 2005 معرفی گردید.
cursor این فیلد مربوط به كنترل Cursor است و مرجع یک Cursor در آن ذخیره می شود
table نتیجه یک کوری را برای عملیاتهای بعدی ذخیره می کند.
برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
پیشنهاد ساخت ایندکس مناسب
3- تعریف ایندکس های مناسب که البته ایجاد نشده اند یا Missing Index
یکی دیگر از فرآیندهای نگهداری ایندکس ها، تعریف ایندکس های مناسب است. اما در پایگاه داده های حجیم چگونه ایندکس هایی را که باید تعریف می کردیم ولی ایجاد نشده اند را پیدا کنیم. آیا راه حلی اتوماتیک وجود دارد که ایندکس های مذکور را بصورت خودکار پیشنهاد و ایجاد کند؟
در صورت نبود ایندکس مناسب = پیشنهاد ایندکس توسط SQL Server
این قابلیت از SQL Server 2005 به بعد اضافه شده است و SQL Server در صورت نبود ایندکس مناسب، پیشنهاد ساخت آنرا می دهد.
روش کار Missing Index ها یا نحوه یپشنهاد ساخت ایندکس های تعریف نشده توسط SQL Server
هر کوئری قسمتی بنام SARG که مخفف واژگان Search Arguments است، دارد. به مثال زیر توجه فرمایید:
SARG
Select f1,f2,... From Tbl01 Where CustomerID=1 And City='Tehran'
Select f1,f2,... From Tbl01 Where City='Tehran'
Select f1,f2,... From Tbl01 Where Name='Ali'هر بار که کوئری ها از سمت Application به پایگاه داده ارسال می شوند قسمت های متمایز شده در مثال بالا در پایگاه داده ذخیره می شوند و بهینه ساز یا Optimizer پایگاه داده با استفاده از آنالیز این داده ها، ساخت ایندکس مناسب را پیشنهاد می دهد.
نکته: داده های مربوط به SARG تا زمانی که سرور Reset نشده باشد قابل دسترس است.
مثال عملی مربوط به Missing Index
در ابتدای مثال های عملی مربوط به Missing Index، کوئری زیر از لحاظ ایندکس گذاری بررسی شده است: (در ادامه مثال ها به مباحث بسیار کاربردی و جالب پرداخته شده است)
Missing Index
SELECT City, StateProvinceID, PostalCode
FROM Person.Address
WHERE StateProvinceID = 9;
GOتوجه: برای مشاهده Missing Index قبل از اینکه کوئری بالا را اجرا نمایید، از آیکن های نوار افقی بالای SQL Server روی آیکن include actual execution plan کلیک نمایید. می توانید از کلیدهای میانبر Ctrl + M استفاده کنید:

در صورتی که کوئری بالا را در SQL Server اجرا کنید، با توجه به اینکه در قسمت Search Arguments ایندکسی برای فیلد StateProvinceID تعریف نشده است، بهینه ساز یا Optimizer پایگاه داده، پیشنهاد ساخت ایندکس را اعلام می کند.
اما برای مشاهده این پیغام، روی تب Execution Plan کلیک کرده و مطابق شکل زیر متن سبز رنگ که متعلق به پیشنهاد ساخت ایندکس است را مشاهده نمایید:
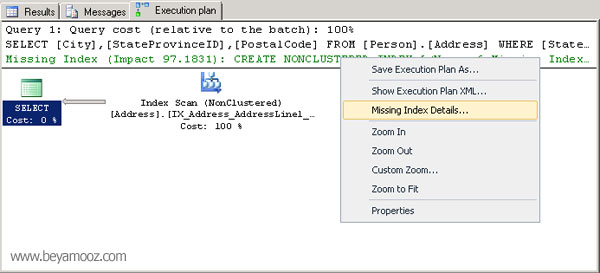
اما اگر روی متن سبز رنگ کلیک کرده و گزینه Missing Index Detail را انتخاب نمایید، در یک صفحه جدید، کوئری ساخت ایندکس در اختیار شما قرار خواهد گرفت:
Missing Index Detail
/*
Missing Index Details from SQLQuery1.sql - SQL2014-TEST.AdventureWorks2012 (sa (67))
The Query Processor estimates that implementing the following index could improve the query cost by 97.1831%.
*/
/*
USE [AdventureWorks2012]
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Person].[Address] ([StateProvinceID])
INCLUDE ([City],[PostalCode])
GO
*/در ادامه بحث Missing Index خواهید دید...!
با خرید جلسه 6 از بسته آموزشی "افزایش کارایی پایگاه داده" موارد زیر را خواهید دید:
- آیا با استفاده از DMVهای موجود می توان Missing Index ها را پیدا کرد؟
- من یک کوئری آماده می خوام که Missing Indexها را پیدا کرده و کوئری ساخت آنها را نیز در اختیارم قرار دهد...!
دسترسی به موارد آموزشی بالا در بسته خریداری شده
- شماره جلسه: 6
- نام فایل ویدئو: 01
- فرمت فایل: mp4.
نقطه شروع بحث بالا (Missing Index) در ویدئو: 15:20
برای خرید و دانلود کاملآموزش پیشرفته SQL Server کلیک کنید.
پیوند بین جداول در SQL
پیوندها برای فراخوانی داده ها از دو یا چند جدول با توجه به ارتباط بین ستون های خاصی از این جدول ها استفاده می شوند.
پیوند (JOIN) بین جداول در SQL
کلید واژه JOIN در دستورات SQL برای ایجاد Query از دو یا چند جدول براساس ارتباط بین ستون های خاصی از جداول استفاده می شود.
جداول در پایگاه داده اغلب به وسیله کلیدها به یکدیگر مرتبط می شوند.
primary key یا کلید اصلی، ستونی(یا ترکیبی از ستون ها) با داده منحصر به فرد و یکتا برای هر سطراست. مقدار کلید اصلی باید یکتا باشد. هدف مرتبط کردن داده ها بین جداول است بدون اینکه داده ها در جداول تکرار شوند.
در جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger توجه کنید که ستون P_Id در جدول فوق کلید اصلی است. این بدان معنی است که هیچ دو سطری نمی تواند مقدار یکسانی داشته باشد. ستون P_Id دو فرد را حتی اگر نام های یکسانی هم داشته باشند، متمایز می کند.
در جدول Orders:
O_Id OrderNo P_Id 1 77895 3 2 44678 3 3 22456 1 4 24562 1 5 34764 15 دقت کنید که ستون O_Id در جدول Orders کلید اصلی می باشد و ستون P_Id در اینجا به نفرات در جدول Persons بدون استفاده از نامشان اشاره دارد.
توجه کنید که ارتباط بین دو جدول به وسیله ستون P_Id می باشد.
تفاوت پیوندها
قبل از اینکه بحث را ادامه دهیم انواع پیوندهایی که می توان استفاده کرد را به همراه تفاوت های آن ها بیان می کنیم:
- JOIN:سطرهایی را که در هر دو جدول تناظر دارند را بر می گرداند.
- LEFT JOIN:تمامی سطرها از جدول سمت چپ را برمی گرداند حتی اگر هیچ تناظری در جدول سمت راست نداشته باشد.
- RIGHT JOIN:تمامی سطرها از جدول سمت راست را برمی گرداند حتی اگر هیچ تناظری در جدول سمت چپ نداشته باشد.
- FULL JOIN: تمام ردیف های موجود در جداول را با وجود حتی یک همخوانی میان جداول بر می گرداند.
برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
تاریخ در SQL
تاریخ در SQL
سخت ترین قسمت کار با Date این است که مطمئن شویم فرمت تاریخی که شما سعی می کنید وارد کنید با فرمت ستون تاریخ در پایگاه داده هم خوانی داشته باشد.
تا زمانی که داده فقط شامل تاریخ باشد، Query شما همان طور که انتظار دارید کار خواهد کرد. اما اگر با بخش زمان درگیر شوید، کار کمی پیچیده خواهد شد.
قبل از صحبت درباره پیچیدگی های کار با تاریخ، توابع مهم آن را با هم مرور می کنیم:
توابع تاریخ در MySQL
جدول زیر، لیستی از مهم ترین توابع تاریخ در MySQL است:
تابع توضیحات NOW() تاریخ و زمان جاری را برمی گرداند CURDATE() تاریخ جاری را برمی گرداند CURTIME() زمان جاری را برمی گرداند DATE() بخش تاریخ را از یک عبارت date/time بیرون می کشد EXTRACT() یکی از بخش های عبارت date/time مانند سال، ماه، روز، ساعت و... را برمی گرداند DATE_ADD() یک فاصله زمانی مشخص را به تاریخ اضافه می کند DATE_SUB() یک فاصله زمانی مشخص را از تاریخ کم می کند DATEDIFF() تعداد روز بین دو تاریخ را برمی گرداند DATE_FORMAT() نمایش تاریخ و زمان در فرمت های مختلف توابع تاریخ در SQL Server
جدول زیر، لیستی از مهم ترین توابع تاریخ در SQL Server است:
تابع توضیحات GETDATE() تاریخ و زمان جاری را برمی گرداند DATEPART() یکی از بخش های عبارت date/time مانند سال، ماه، روز، ساعت و... را برمی گرداند DATEADD() یک فاصله زمانی مشخص را به تاریخ اضافه یا کم می کند DATEDIFF() زمان بین دو تاریخ را برمی گرداند CONVERT() نمایش تاریخ و زمان در فرمت های مختلف انواع داده های تاریخ در SQL
MySQL:
- DATE - format YYYY-MM-DD
- DATETIME - format: YYYY-MM-DD HH:MM:SS
- TIMESTAMP - format: YYYY-MM-DD HH:MM:SS
- YEAR - format YYYY or YY
SQL Server:
- DATE - format YYYY-MM-DD
- DATETIME - format: YYYY-MM-DD HH:MM:SS
- SMALLDATETIME - format: YYYY-MM-DD HH:MM:SS
- TIMESTAMP - format: a unique number
 توجه: زمانی که یک جدول جدید تعریف می کنید باید برای هر ستون، Data Type آنرا مشخص کنید.
توجه: زمانی که یک جدول جدید تعریف می کنید باید برای هر ستون، Data Type آنرا مشخص کنید.اگر مایل هستید کلیه ی انواع داده را مرور کنید به مطلب SQL Data Types مراجعه نمایید.
کار با تاریخ در SQL
توجه: اگر خودتان را با بخش زمان درگیر نکنید، براحتی می توانید دو تاریخ مختلف را با هم مقایسه کنید!فرض کنید جدول "Orders" را داریم:
OrderId ProductName OrderDate 1 Geitost 2008-11-11 2 Camembert Pierrot 2008-11-09 3 Mozzarella di Giovanni 2008-11-11 4 Mascarpone Fabioli 2008-10-29 حالا می خواهیم رکوردهایی با تاریخ "2008-11-11" را انتخاب کنیم.
از Query زیر استفاده می کنیم:
SELECT * FROM Orders WHERE OrderDate='2008-11-11'نتیجه به شکل زیر خواهد بود:
OrderId ProductName OrderDate 1 Geitost 2008-11-11 3 Mozzarella di Giovanni 2008-11-11 حالا، فرض کنید که جدول "Orders" شبیه زیر باشد. (بخش زمان به فیلد OrderDate اضافه شده است)
OrderId ProductName OrderDate 1 Geitost 2008-11-11 13:23:44 2 Camembert Pierrot 2008-11-09 15:45:21 3 Mozzarella di Giovanni 2008-11-11 11:12:01 4 Mascarpone Fabioli 2008-10-29 14:56:59 اگر از Query بالا استفاده کنیم نتیجه ای نخواهیم داشت، بنابراین اگر می خواهید Queryی ساده ای داشته باشید، اجازه ندهید بخش زمان در تاریخ وارد شود.
توجه: در SQL Server با استفاده از تابع ()substring می توان قسمت تاریخ را بیرون کشید و سپس مقایسه کرد.SELECT * FROM Orders WHERE substring(OrderDate,1,10)='2008-11-11'برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
دستور delete در SQL
دستور DELETE برای حذف رکوردها در یک جدول استفاده می شود.
دستور DELETE
دستور DELETE برای حذف سطرها در یک جدول استفاده می شود.
فرم دستور DELETE
DELETE FROM table_name
WHERE some_column=some_valueتوجه: به بند WHERE در فرم دستور DELETE توجه داشته باشید. بند WHERE مشخص می کند کدام رکورد یا رکوردها باید حذف شوند. اگر بند WHERE را پاک کنید تمام رکوردها حذف خواهند شد.مثال DELETE
در جدول Persons
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Johan Bakken 2 Stavanger 5 Tjessem Jakob Nissestien 67 Sandnes می خواهیم شخص "Tjessem, Jakob" را از جدول Persons پاک کنیم.
از عبارت SQLزیر استفاده می کنیم:
DELETE FROM Persons
WHERE LastName='Tjessem' AND FirstName='Jakob'جدول Persons به شکل زیر خواهد شد:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Johan Bakken 2 Stavanger Delete کردن تمام سطرها
می توان تمام رکوردهای یک جدول را بدون Delete کردن جدول پاک کرد. این بدان معناست که ساختار، ویژگی ها و index (شاخص های جدول) به قوت خود باقی می مانند.
DELETE FROM table_name
or
DELETE * FROM table_nameتوجه: بسیار مواظب باشید اگر رکوردهایی را DELETE کردید دیگر نمی توانید آنها را برگردانید.دستور distinct در SQL
در این فصل دستور SELECT DISTINCT را توضیح می دهیم.
دستور SELECT DISTINCT
در یک جدول بعضی ستونها ممکن است داده های تکراری داشته باشند. بعضی مواقع شما می خواهید لیستی تهیه کنید که تنها داده های یکتا در آن باشد. یعنی همه داده ها را نشان دهد و داده های تکراری را یکبار نشان دهد.
کلید واژه DISTINCT برای برگرداندن داده های یکتا و متمایز به کار برده می شود.
فرم دستور SELECT DISTINCT:
SELECT DISTINCT column_name(s)
FROM table_nameمثال:
در جدول زیر می خواهیم داده های یکتا از ستون City را بدست آوریم:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger از عبارت زیر برای این منظور استفاده می کنیم:
SELECT DISTINCT City FROM Persons
نتیجه به شکل زیر خواهد بود:
City Sandnes Stavanger دستور insert into در SQL
دستور INSERT INTO برای درج کردن(واردکردن) رکورد جدید به جدول استفاده می شود.
دستور INSERT INTO
دستور INSERT INTO برای درج کردن (واردکردن) سطر جدید به جدول استفاده می شود.
فرم دستور INSERT INTO
می توان دستور INSERT INTO را به دو صورت نوشت:
در فرم اول نام ستونهایی که اطلاعات در آن درج می شوند مشخص نمی شود و تنها مقادیر مشخص می شود.
INSERT INTO table_name
VALUES (value1, value2, value3,...)در فرم دوم هم نام ستون و هم مقادیری که باید درج شوند مشخص می شوند.
INSERT INTO table_name (column1, column2, column3,...)
VALUES (value1, value2, value3,...)مثال:
جدول "Persons" را داریم:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger حالا می خواهیم تا سطر جدیدی را به جدول فوق اضافه کنیم.
از عبارت SQLزیر استفاده می کنیم:
INSERT INTO Persons
VALUES (4,'Nilsen', 'Johan', 'Bakken 2', 'Stavanger')جدول "Persons" به شکل زیر خواهد شد:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Johan Bakken 2 Stavanger سطر جدید در انتهای جدول اضافه می شود.
داده را تنها به ستون های مشخصی اضافه کنید
می توان تنها داده را به ستون های مشخصی اضافه کرد.
عبارت SQL زیر سطر جدیدی را اضافه می کند اما تنها داده ها را به ستون های "P_Id" و "LastName" و "FirstName" اضافه می کند.
INSERT INTO Persons (P_Id, LastName, FirstName)
VALUES (5, 'Tjessem', 'Jakob')بنابراین جدول "Persons" به شکل زیر خواهد شد:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Johan Bakken 2 Stavanger 5 Tjessem Jakob دستور update در SQL
دستور UPDATE برای به روز رسانی(تغییر) رکوردهای مشخص(از مقدار فعلی به مقدار جدید) در جدول استفاده می شود.
دستور UPDATE
دستور UPDATE برای به روز رسانی رکوردهای موجود در یک جدول استفاده می شود.
فرم دستور UPDATE:
UPDATE table_name
SET column1=value, column2=value2,...
WHERE some_column=some_valueتوجه: به بند WHERE در دستور UPDATE توجه کنید. بند WHERE مشخص می کند کدام رکورد یا رکوردها باید UPDATE شوند. اگر شما بند WHERE را حذف کنید تمام رکوردها UPDATE می شوند.مثال:
در جدول Persons
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Johan Bakken 2 Stavanger 5 Tjessem Jakob می خواهیم اطلاعات شخص "Tjessem, Jakob" را در جدول فوق update کنیم(تغییر دهیم).
از عبارت SQLزیر استفاده می کنیم:
UPDATE Persons
SET Address='Nissestien 67', City='Sandnes'
WHERE LastName='Tjessem' AND FirstName='Jakob'جدول Persons به این شکل در خواهد آمد:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Johan Bakken 2 Stavanger 5 Tjessem Jakob Nissestien 67 Sandnes هشدار در مورد دستور UPDATE
هنگام UPDATE کردن رکوردها دقت کنید. اگر بند WHERE را در مثال بالا حذف کنیم یعنی دستور به صورت زیر شود:
UPDATE Persons
SET Address='Nissestien 67', City='Sandnes'نتیجه به شکل زیر خواهد شد یعنی تمام رکوردها به یک مقدار تغییر می کنند:
P_Id LastName FirstName Address City 1 Hansen Ola Nissestien 67 Sandnes 2 Svendson Tove Nissestien 67 Sandnes 3 Pettersen Kari Nissestien 67 Sandnes 4 Nilsen Johan Nissestien 67 Sandnes 5 Tjessem Jakob Nissestien 67 Sandnes دستور زبان SQL
جداول پایگاه داده
یک پایگاه داده از یک یا چند جدول تشکیل می شود. هر جدول با یک نام مشخص می شود. (مثلا "Customers" یا "Orders") جداول حاوی رکوردها یا سطرهای حاوی داده می باشند.
در زیر جدولی با نام "Persons" را مشاهده می کنید:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger جدول فوق شامل سه رکورد (هر رکورد برای یک فرد) و پنج ستون (P_Id, LastName, FirstName, Address, and City) می باشد.
عبارات SQL:
غالب عملیات هایی که نیاز دارید روی یک پایگاه داده انجام شود توسط عبارات SQL انجام می شوند.
عبارت SQLزیر، تمام رکوردهای جدول "Persons" را انتخاب می کند:
SELECT * FROM Persons
در این خودآموز همه چیز در مورد عبارات SQL آموزش داده خواهد شد.
به یاد داشته باشید که...
SQL به کوچکی و بزرگی حروف حساس نمی باشد. (case sensitive نمی باشد)
سمیکالن ";" بعد از عبارات SQL نیاز است یا نه؟
بعضی از سیستم های پایگاه داده به سمیکالن ";" در انتهای عبارات SQL نیاز دارند.
سمیکالن ";" یک روش استاندارد برای جدا کردن عبارات SQL در سیستمهای پایگاه داده ای می باشد که اجازه می دهند بیش از یک عبارت SQL در یک ارتباط به سرور اجرا شوند.
ما از MS Access و SQL Server استفاده می کنیم و نیازی نیست که بعد از هر عبارت SQL سمیکالن بگذاریم اما در بعضی از برنامه های پایگاه داده ما باید از سمیکالن استفاده کنیم.
SQL DML و SQL DDL
SQL را می توان به دو بخش تقسیم کرد: زبان دستکاری داده Data Manipulation Language یا DML و زبان تعریف داده Data Definition Language یا DDL.
بخش SQL DML:
- SELECT: داده را از یک پایگاه داده بیرون می کشد.
- UPDATE : داده ای را در یک پایگاه داده به روز رسانی می کند(تغییر می دهد).
- DELETE: داده را از یک پایگاه داده حذف می کند.
- INSERT INTO: داده جدیدی را به پایگاه داده اضافه می کند.
بخش SQL DDL:این بخش از دستورات SQL اجازه می دهد تا جداول پایگاه داده ایجاد یا حذف شوند. همچنین شاخصها (indexes) و کلیدها را تعریف می کند، ارتباط بین جداول و محدودیت ها را مشخص می کند.
- CREATE DATABASE: یک پایگاه داده جدید ایجاد می کند.
- ALTER DATABASE: یک پایگاه داده را تغییر می دهد.
- CREATE TABLE: یک جدول جدید ایجاد می کند.
- ALTER TABLE : یک جدول را تغییر می دهد.
- DROP TABLE : یک جدول را حذف می کند.
- CREATE INDEX : یک شاخص یا index (کلید جستجو) ایجاد می کند.
- DROP INDEX: یک شاخص را حذف می کند.
عبارت full join در SQL
کلید واژه FULL JOIN
کلید واژه FULL JOIN تمام ردیف های موجود در جداول را با وجود حتی یک همخوانی میان جداول بر می گرداند.
فرم دستور FULL JOIN:
SELECT column_name(s)
FROM table_name1
FULL JOIN table_name2
ON table_name1.column_name=table_name2.column_nameمثال:
جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger جدول Orders:
O_Id OrderNo P_Id 1 77895 3 2 44678 3 3 22456 1 4 24562 1 5 34764 15 می خواهیم تمام افراد و سفارش هایشان، و نیز تمام سفارش ها به همراه افراد مربوطه را لیست کنیم:
از دستور زیر استفاده می کنیم:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
FULL JOIN Orders
ON Persons.P_Id=Orders.P_Id
ORDER BY Persons.LastNameنتیجه به شکل زیر خواهد شد:
LastName FirstName OrderNo Hansen Ola 22456 Hansen Ola 24562 Pettersen Kari 77895 Pettersen Kari 44678 Svendson Tove 34764 کلید واژه FULL JOIN تمام سطرهایی که در جدول چپ (Persons) و تمام سطرهای جدول راست (Orders) وجود دارد را بر می گرداند. اگر سطری در جدول Persons وجود دارد که تناظری در جدول Orders ندارد یا اگر سطری در جدول Orders وجود دارد که تناظری در جدول Persons ندارد این سطرها نیز در جدول نتیجه نمایش داده خواهند شد.
عبارت inner join در SQL
عبارت INNER JOIN
عبارت کلیدی INNER JOIN سطرهایی را برمی گرداند که در هر دو جدول حداقل یک داده متناظر در ستون های مرتبط شده داشته باشد.
فرم عبارت INNER JOIN:
SELECT column_name(s)
FROM table_name1
INNER JOIN table_name2
ON table_name1.column_name=table_name2.column_nameمثال:
جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger جدول Orders:
O_Id OrderNo P_Id 1 77895 3 2 44678 3 3 22456 1 4 24562 1 5 34764 15 می خواهیم تمامی افراد را به همراه سقارشاتشان لیست کنیم.
از دستور زیر استفاده می کنیم:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
INNER JOIN Orders
ON Persons.P_Id=Orders.P_Id
ORDER BY Persons.LastNameنتیجه به شکل زیر خواهد بود:
LastName FirstName OrderNo Hansen Ola 22456 Hansen Ola 24562 Pettersen Kari 77895 Pettersen Kari 44678 عبارت کلیدی INNER JOIN سطرهایی که حداقل یک تناظر در دو جدول داشته باشد را برمی گرداند. اگر فردی در جدول Persons وجود دارد که تناظری در جدول Orders ندارد،آن فرد لیست نمی شود.
برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServerکلیک کنید.
عبارت left join در SQL
عبارت LEFT JOIN
کلید واژه LEFT JOIN تمام سطرهای جدول سمت چپ (table_name1) را برمی گرداند حتی اگر هیچ داده متناظری برای آن در جدول سمت راست (table_name2) وجود نداشته باشد.
فرم عبارت LEFT JOIN:
SELECT column_name(s)
FROM table_name1
LEFT JOIN table_name2
ON table_name1.column_name=table_name2.column_nameدر بعضی از پایگاه داده ها LEFT JOIN به شکل LEFT OUTER JOIN می باشد.
مثال:
جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger جدول Orders:
O_Id OrderNo P_Id 1 77895 3 2 44678 3 3 22456 1 4 24562 1 5 34764 15 می خواهیم تمام افراد را لیست کنیم حتی اگر سفارشی در مقابل نام آن وجود نداشته باشد.
از دستور زیر استفاده می کنیم:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
LEFT JOIN Orders
ON Persons.P_Id=Orders.P_Id
ORDER BY Persons.LastNameنتیجه به شکل زیر خواهد شد:
LastName FirstName OrderNo Hansen Ola 22456 Hansen Ola 24562 Pettersen Kari 77895 Pettersen Kari 44678 Svendson Tove کلید واژه LEFT JOIN تمام سطرهای جدول سمت چپ (Persons) را برمی گرداند حتی اگر هیچ داده متناظری برای آن در جدول سمت راست (Orders) وجود نداشته باشد.
برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
عبارت order by در SQL
کلمه کلیدی ORDER BY برای مرتب کردن نتیجه پرس و جو استفاده می شود.
کلمه کلیدی ORDER BY
دستور ORDER BY برای مرتب کردن نتیجه پرس و جو بر اساس ستون مشخص شده استفاده می شود.
در دستور ORDER BY به صورت پیش فرض، رکوردها به صورت صعودی (از کوچک به بزرگ) مرتب می شوند.
اگر می خواهید رکوردها را نزولی (از بزرگ به کوچک) مرتب کنید، باید از کلید واژه DESC استفاده کنید.
فرم کلی ORDER BY:
SELECT column_name(s)
FROM table_name
ORDER BY column_name(s) ASC|DESCمثال:
در جدول "Persons"
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Tom Vingvn 23 Stavanger می خواهیم تمام افراد ازجدول بالا را انتخاب کنیم اما افراد بر اساس نام خانوادگی شان مرتب شده باشند.
از عبارت SELECT زیر استفاده می کنیم:
SELECT * FROM Persons
ORDER BY LastNameresult-set به این صورت می شود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 4 Nilsen Tom Vingvn 23 Stavanger 3 Pettersen Kari Storgt 20 Stavanger 2 Svendson Tove Borgvn 23 Sandnes مثال ORDER در حالت DESC
حالا می خواهیم تمام افراد جدول بالا را بر اساس ترتیب نزولی نام خانوادگی شان انتخاب کنیم.
از عبارت SELECT زیر استفاده می کنیم:
SELECT * FROM Persons
ORDER BY LastName DESCresult-set به صورت زیر خواهد بود:
P_Id LastName FirstName Address City 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger 4 Nilsen Tom Vingvn 23 Stavanger 1 Hansen Ola Timoteivn 10 Sandnes عبارت right join در SQL
عبارت RIGHT JOIN
کلید واژه RIGHT JOIN تمام سطرهای جدول سمت راست (table_name2) را برمی گرداند حتی اگر هیچ داده متناظری برای آن در جدول سمت چپ (table_name1) وجود نداشته باشد.
فرم عبارت RIGHT JOIN:
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_nameدر بعضی از پایگاه داده ها RIGHT JOIN به شکل RIGHT OUTER JOIN می باشد.
مثال:
جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger جدول Orders
O_Id OrderNo P_Id 1 77895 3 2 44678 3 3 22456 1 4 24562 1 5 34764 15 می خواهیم تمام سفارشات (orderها) را لیست کنیم حتی اگر نام فردی در مقابل آن سفارش وجود نداشته باشد.
از دستور زیر استفاده می کنیم:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
RIGHT JOIN Orders
ON Persons.P_Id=Orders.P_Id
ORDER BY Persons.LastNameجدول نتایج به شکل زیر خواهد بود:
LastName FirstName OrderNo Hansen Ola 22456 Hansen Ola 24562 Pettersen Kari 77895 Pettersen Kari 44678 34764 کلید واژه RIGHT JOIN تمام سطرهای جدول سمت راست (Orders) را برمی گرداند حتی اگر هیچ داده متناظری برای آن در جدول سمت چپ (Persons) وجود نداشته باشد.
برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
عملگر between در SQL
عملگر BETWEEN در عبارت WHERE برای انتخاب محدوده ای از داده ها بین دو مقدار استفاده می شود.
عملگر BETWEEN
عملگر BETWEEN یک محدوده از داده ها بین دو مقدار را انتخاب می کند. مقدارها می توانند اعداد، متن ها و تاریخ باشد.
نکته اضافه: از NOT BETWEEN هم می شود استفاده کرد.فرم عملگر BETWEEN:
SELECT column_name(s)
FROM table_name
WHERE column_name
BETWEEN value1 AND value2مثال 1
در جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger می خواهیم افرادی را انتخاب کنیم که نام خانوادگی آنها از نظر الفبایی بین Hansen و Pettersen می باشد.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE LastName
BETWEEN 'Hansen' AND 'Pettersen'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes توجه: عملگر BETWEEN در پایگاه داده های متفاوت رفتارهای متفاوتی دارد.در بعضی از پایگاه داده ها، افرادی با نام خانوادگی Hansen یا Pettersen لیست نمی شوند، زیرا عملگر BETWEEN فیلدهای بین دو مقدار را بجز مقادیر ابتدا و انتهای محدوده برمی گرداند.
در بعضی دیگر از پایگاه داده ها، افرادی با نام خانوادگی Hansen یا Pettersen لیست می شوند، زیرا عملگر BETWEEN فیلدهای بین دو مقدار رابه همراه مقادیر ابتدا و انتهای محدوده برمی گرداند.
در بعضی دیگر از پایگاه داده ها، افرادی با نام خانوادگی Hansen لیست می شوند اما نام خانوادگی Pettersen در لیست نمی آید (مانند مثال بالا)، زیرا عملگر BETWEEN فیلدهای بین دو مقدار رابه همراه مقدار ابتدایی و بدون مقدار انتهایی محدوده برمی گرداند.
بنابراین: پایگاه داده خود را کنترل کنید که چگونه با عملگر BETWEEN رفتار می کند.
مثال 2
برای نمایش افرادی که خارج از محدوده هستند از دستور NOT BETWEEN استفاده کنید:
SELECT * FROM Persons
WHERE LastName
NOT BETWEEN 'Hansen' AND 'Pettersen'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServerکلیک کنید.
عملگر in در SQL
عملگر IN
عملگر IN به شما این امکان را می دهد که چندین ارزش را در عبارت WHERE مشخص کنید.
نکته اضافه: از NOT IN هم می توانید استفاده کنید.فرم عملگر IN:
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1,value2,...)مثال:
در جدول Persons:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger می خواهیم افرادی را که نام خانوادگی آنها "Hansen" یا "Pettersen" می باشد را انتخاب کنیم:
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE LastName IN ('Hansen','Pettersen')جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 3 Pettersen Kari Storgt 20 Stavanger برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.
عملگر like در SQL
عملگر LIKE
عملگر LIKE در بند WHERE برای پیدا کردن یک الگوی خاص در یک ستون استفاده می شود.
فرم عملگر LIKE:
SELECT column_name(s)
FROM table_name
WHERE column_name LIKE patternمثال عملگر LIKE
در جدول Persons
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger می خواهیم افرادی که در شهری زندگی می کنند که با حرف s شروع می شود را انتخاب کنیم.
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE City LIKE 's%'توجه کنید که یک الگو را در بین کوتیشن می نویسیم.
علامت % جانشینی برای یک یا چند کاراکتر در الگو استفاده می شود که می تواند این کاراکترها هر چیزی باشد.
جدول نتایج بدین شکل خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes 3 Pettersen Kari Storgt 20 Stavanger حال اگر بخواهیم افرادی را انتخاب کنیم که در شهری زندگی می کنند که به کاراکتر S ختم می شوند از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE City LIKE '%s'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes حال اگر بخواهیم افرادی را انتخاب کنیم که در شهری زندگی می کنند که حاوی کلمه "tav" در نام شهر خود می باشند از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE City LIKE '%tav%'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 3 Pettersen Kari Storgt 20 Stavanger می شود افرادی را انتخاب کرد که در شهری زندگی می کنند که حاوی کلمه "tav" نمی باشند. این کار را با کلید واژه NOT قبل از عملگر LIKE انجام می دهیم. (NOT LIKE)
از دستور زیر استفاده می کنیم:
SELECT * FROM Persons
WHERE City NOT LIKE '%tav%'جدول نتایج به شکل زیر خواهد بود:
P_Id LastName FirstName Address City 1 Hansen Ola Timoteivn 10 Sandnes 2 Svendson Tove Borgvn 23 Sandnes برای مشاهده فیلم های آموزشی مقدماتی تا پیشرفته پایگاه داده SQLServer کلیک کنید.

