

آموزش پیشرفته SQL Server (جلسه چهارم) – آشنایی با NonClustered Index
آشنایی با NonClustered Index ، قسمتی از آموزش پیشرفته SQL Server است، پیشنهاد می شود قبل از مطالعه ی آشنایی با NonClustered Index ، قسمت های قبلی را مطالعه فرمایید.
NonClustered Index چیست؟
NonClustered Index یکی از ساختارهای ذخیره سازی داده در جداول می باشد که بر اساس آن داده ها در ازای یک فیلد خاص که توسط ما مشخص می شود دارای نظم و ترتیب بوده و فضای ذخیره سازی داده های شرکت کننده در ایندکس در مکانی مجزا است. موارد زیر را میتوان از ویژگیهای آن دانست:
- Page های مربوط به این نوع ایندکس از نوع Index Page می باشد.
- ساختار ذخیره سازی NonClustered Index از نوع B-Tree می باشد.
- تعداد NonClustered Index که می توان برای یک جدول تعریف نمود 999 عدد می باشد.
ساختار NonClustered Index:
شکل زیر قسمتهای مختلف یک NonClustered Index را نشان می دهد: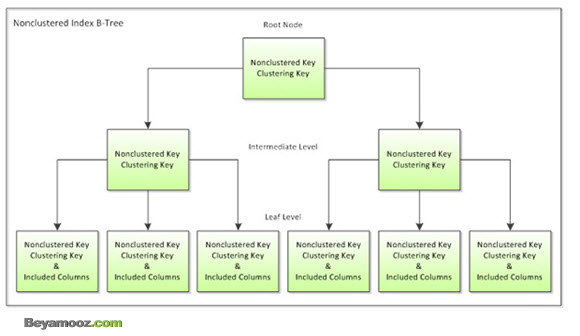
همانطور که در شکل مشاهده می شود یک NonClutered Index شامل لایه هایRoot,Intermediate و Leaf می باشد که جدا از داده ها در فایل ایندکس نگهداری می شوند. در لایه آخر یعنی Leaf Level هر خانه به یک رکورد در محیط فیزیکی داده ها اشاره دارد، به این صورت که قسمت اول آن به شماره Page و قسمت دوم به شماره رکورد موجود در آن Page اشاره می نماید.
بررسی ساختار NonClutered Index:
NonClutered Index ها به دو دسته تقسیم می شوند:
- یک دسته آنهایی هستند که روی یک Clustered Index تعریف می شوند که در این نوع از ایندکس بعد از اینکه از ریشه تا برگ در درخت NonClutered Index پیمایش شد در صورتیکه داده های مورد جستجو به همراه کلید ایندکس موجود نبود،برای یافتن داده به سراغ درخت Clutered Index رفته و آن را نیز تا رسیدن به داده اصلی پیمایش می نماید.شکل زیر ساختار این نوع ایندکس را نمایش می دهد:
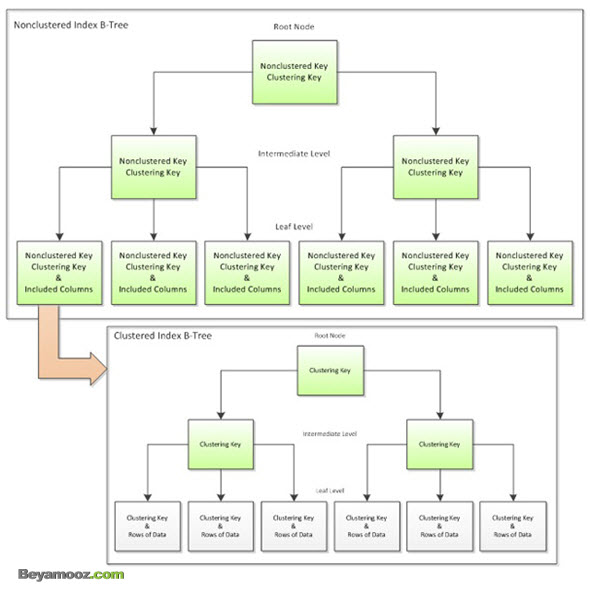
- نوع دوم آن دسته ای هستند که روی یک جدول Heap پیاده سازی می شوند که در این نوع نیز در صورتیکه بع از پیمایش درخت ایندکس و رسیدن به لایه برگ درخت داده های مورد جستجو به همراه کلید ایندکس نبود باید پیمایشی روی جدول Heap برای یافتن رکوردهای مورد نظر صورت گیرد. شکل زیر ساختار این نوع ایندکس را نشان می دهد:
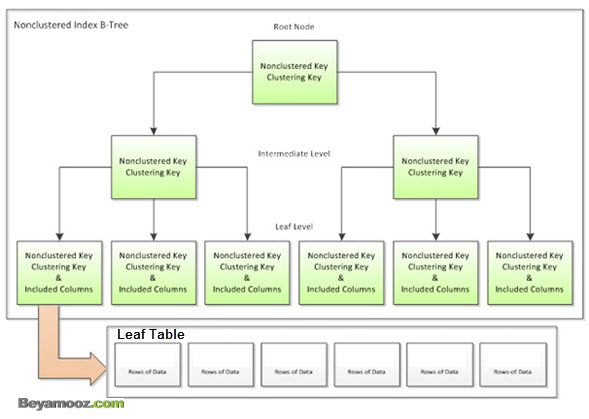
Bookmark در یک NonClustered Index:
Bookmark در حقیقت نحوه ارتباط یک عنصر Leaf Level به یک رکورد در یک جدول Heap و یا Clustered گفته می شود که مطابق با شکل زیر این نوع ارتباط در جدول Heap از دو قسمت تشکیل شده است که قسمت اول آن شماره صفحه و قسمت دوم آن شماره رکورد در صفحه را بیان می نماید: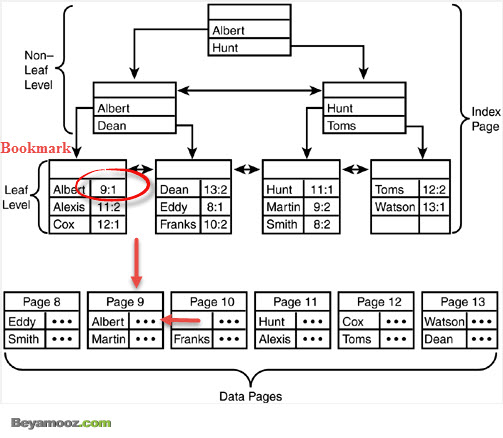
اما در یک جدول Clustered این مقدار در حقیقت برابر با مقدار کلید ایندکس می باشد که این نوع از Bookmark در شکل زیر نمایش داده می شود: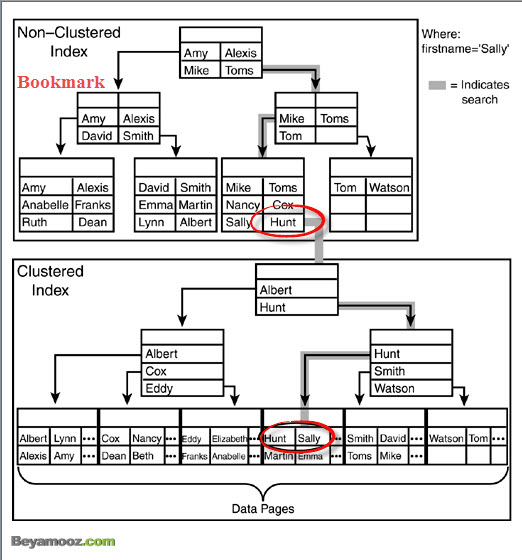
بررسی مفهوم Lookup در یک NonClustered Index:
- به مراجعه از Leaf Level به Data Level گفته می شود.
- در هنگام استفاده از NonClustered Index رخ می دهد.
- دو نوع است 1-Key Lookup که در هنگام استفاده از یک NonClustered Index روی یک جدول Clustered رخ می دهد و 2-RID Lookup که هنگام استفاده از یک NonClustered Index روی یک جدول Heap اتفاق می افتد.
هر دو مورد ذکر شده در بالا در شکلهای آمده در قسمت Bookmark به خوبی نشان داده شده است.
 توجه: هر چه تعداد Lookup در یک query بیشتر باشد IO بیشتر و Cost بالاتر را منجر می شود، بنابراین ما باید نسبت به کم نمودن تعداد LookUp با استفاده از تکنیکهایی مانند Cover Index تلاش نماییم. .
توجه: هر چه تعداد Lookup در یک query بیشتر باشد IO بیشتر و Cost بالاتر را منجر می شود، بنابراین ما باید نسبت به کم نمودن تعداد LookUp با استفاده از تکنیکهایی مانند Cover Index تلاش نماییم. .
در ادامه بحث آشنایی با NonClustered Index خواهید دید ...!
1-آشنایی کامل با NonClustered Index.
2- آموزش تحلیل Execution Plan در رابطه با NonClustered Index.
دسترسی به موارد آموزشی بالا در بسته خریداری شده
- شماره جلسه: 4
- نام فایل ویدئو: 02
- فرمت فایل: mp4.
نقطه شروع بحث بالا (آشنایی با NonClustered Index ) در ویدئو: 00:30

