

آشنایی با Statistics در SQL Server
یکی دیگر از آیتم هایی که باعث افزایش کارآیی و سرعت بانک اطلاعاتی می شود، Statistics است و هدف استفاده از Statisticsها انتخاب یک ایندکس مناسب برای کوئری هاست.
statistics چیست؟
با استفاده از Statisticsها می توان میزان پراکندگی مقادیر فیلدها را نمایش داد. یعنی برای فیلدی مثل City می توان تعداد تکرارهای شهر "اصفهان" و یا "تهران" را مشاهده نمود.
حالا شاید سوال کنید، نگهداری آمار پراکندگی مقادیر داده ها چه کاربری دارد؟
نگهداری آمار پراکندگی مقادیر داده ها در مفهومی بنام Cardinality Estimation استفاده می شود. همان طور که می دانید روی یک جدول ممکن است چندین ایندکس مختلف تعریف شده باشد. حالا SQL Server با استفاده از Cardinality Estimation تشخیص می دهد که از کدام ایندکس استفاده نماید.
در واقع Cardinality Estimation می تواند تعداد رکوردهای بازگشتی روی فیلترهای مختلف مثل Group By و Join و Where به ازای ایندکس های تعریف شده، تخمین بزند و ایندکسی که عدد کوچکتری برای آن تخمین زده شده است را انتخاب می کند.
دلیل انتخاب عدد کوچکتر خیلی ساده است، و آن به خاطر این است که جستجو بین تعداد رکوردهای کمتر، سریع تر خواهد بود.
مثال: انتخاب ایندکس مناسب از بین دو ایندکس مختلف:
لطفاً به کوئری زیر توجه فرمایید:
یک کوئری ساده
SELECT OrderID,EmployeeID,ShipCountry FROM Orders2
WHERE EmployeeID=5 AND ShipCountry='USA'
تصور فرمایید، برای اجرای کوئری بالا، دو ایندکس زیر قبلاً تعریف شده است:
تعریف دو ایندکس مختلف
INCLUDE (OrderID,EmployeeID)
GO
CREATE NONCLUSTERED INDEX IX_EmployeeID ON Orders2(EmployeeID)
INCLUDE (OrderID,ShipCountry)
برای کوئری مذکور، کدام یک از ایندکس های بالا، مناسب تر است؟ در ادامه این آموزش به جواب این سوال خواهیم رسید ...!
محل Statisticsها در پایگاه داده
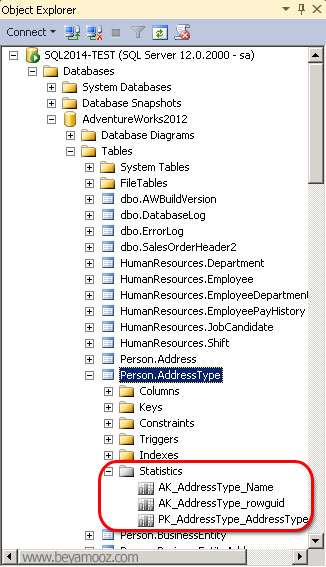
همان طور که در شکل زیر مشاهده می کنید، هر جدول در پایگاه داده، شامل یک زیرمجموعه Statistics می باشد که با باز کردن آن، اطلاعات آماری مربوط به آن جدول در اختیار قرار خواهد گرفت:
Statistics چگونه ایجاد می شود؟
Statistics به سه روش ایجاد می شود:
- ایجاد Statistics بصورت خودکار
- ایجاد Statistics زمان ایجاد ایندکس
- ایجاد Statistics توسط کاربر
در ادامه هر کدام از موارد بالا را بصورت خودکار توضیح خواهیم داد.
1- ایجاد Statistics بصورت خودکار
- در اینجا Statisticsها توسط Query Optimizer ایجاد می شوند.
- این Statisticsها همیشه به ازای یک فیلد ایجاد می شوند.
- عملیات ایجاد Statistics را می توان از طریق Properties پایگاه داده، غیرفعال نمود (به هیچ عنوان پیشنهاد نمی شود)
- عدم پشتیبانی از Filtered Statistics
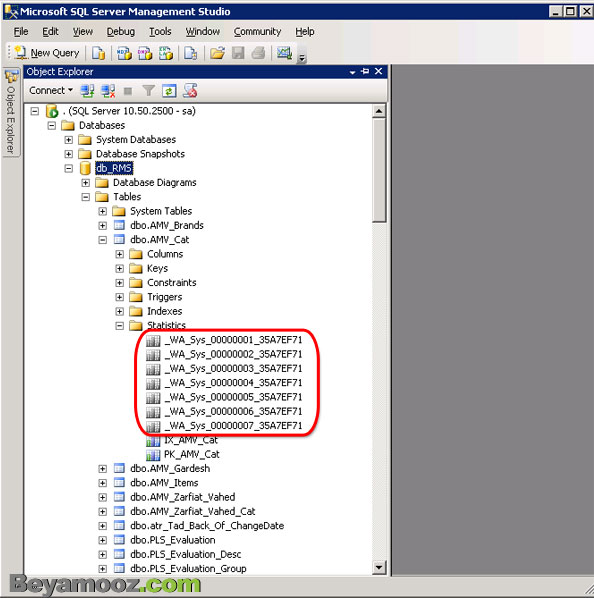
مطابق شکل زیر، اگر در پنل Object Explorer به زیرگزینه های Statistics توجه کنید، مواردی را خواهید دید که نامگذاری آنها غیرعادی است. این موارد جزء Statisticsهایی هستند که بصورت خودکار ایجاد شده اند:
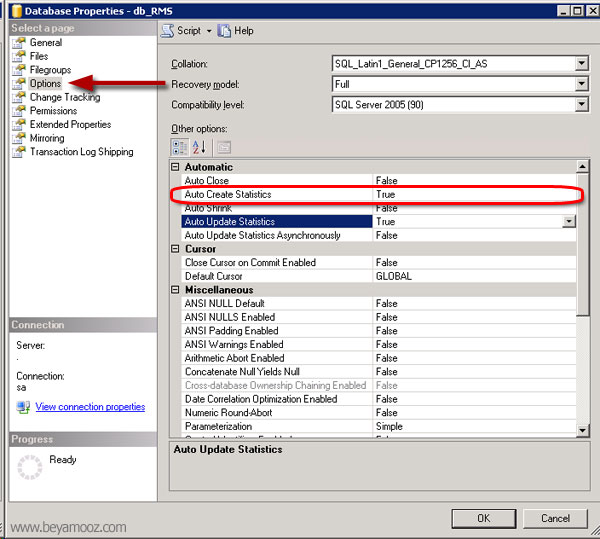
بصورت پیشفرض عملیات ایجاد Statisticها فعال است، اما برای غیر فعال کردن ایجاد خودکار Statistics در پنل Object Explorer روی پایگاه داده مورد نظرتان راست کلیک کرده و گزینه Properties را انتخاب نمایید، سپس در پنجره Database properties از سمت چپ گزینه Option را انتخاب نمایید و نهایتاً از سمت راست پنجره گزینه auto Create Statistics را تنظیم نمایید:
مثال 1: اسکریبت تنظیم گزینه AUTO_CREATE_STATISTICS
AUTO_CREATE_STATISTICS
ALTER DATABASE Northwind
SET AUTO_CREATE_STATISTICS ON WITH NO_WAIT
مثال 2: نحوه ی ایجاد Statistics بصورت خودکار:
Select بدون شرط
SELECT * FROM Person_Contact
GO
در مثال بالا، بدلیل اینکه قسمت Where وجود ندارد، هیچ Stats ی ایجاد نخواهد شد، اما اگر قسمت Where را اضافه کنید، Query Optimizer آنرا ایجاد خواهد کرد:
Select دارای شرط
SELECT * FROM Person_Contact
WHERE LastName = N'Andersen'
اگر به قسمت Statistics جدول Person_Contact مراجعه کنید، خواهید دید که به ازای فیلد LastName یک Stats ایجاد شده است.
مثال 3: نمایش لیست Stats های یک جدول خاص
با استفاده از پروسیجر SP_HELPSTATS می توان لیست کلیه Statistics های یک جدول خاص را نمایش داد:
نمایش لیست Stats های یک جدول خاص
SP_HELPSTATS N'Table_Name', 'ALL' 2- ایجاد Statistics زمان ایجاد ایندکس
- زمان ایجاد ایندکس ها، بصورت اتوماتیک یک Stats، همنام با ایندکس ایجاد خواهد شد.
- در اینجا، امکان ایجاد Statistics به ازای چند فیلد وجود دارد.
- پشتیبانی از Filtered Statistics
مثال 1: در مثال زیر، ابتدا یک Index با نام Phone ایجاد کرده ایم، حالا اگر توسط پروسیجر SP_HELPSTATS لیست کلیه Stats های جدول مربوطه را نمایش دهید، خواهید دید که یک Stats با نام Phone نیز ایجاد شده است:
ایجاد خودکار Stats هنگام ایجاد ایندکس
CREATE NONCLUSTERED INDEX Phone on Person_Contact(Phone)
GO
SP_HELPSTATS N'Person_Contact', 'ALL'
GO
3- ایجاد Statistics توسط کاربر
- Statistics توسط کاربر ایجاد خواهد شد.
- امکان ایجاد Statistics به ازای چند فیلد وجود دارد.
- پشتیبانی از Filtered Statistics
مثال 1: نحوه ی ساخت Statistics توسط کاربر:
ساخت Stats توسط کاربر
CREATE STATISTICS Stats_Name ON
Table_Name(Fild_names)
بررسی اجزاء مربوط به Statistics
Statisticsها شامل سه قسمت زیر هستند:
- Stat Header
- Density Vector
- Histogram
در ادامه به اختصار هر کدام از موارد بالا را توضیح خواهیم داد.
1- Stat Header چیست؟
Stat Header شامل اطلاعات زیر می باشد:
- مشخصات کلی Statistics را نمایش می دهد.
- آخرین وضیعت بروز رسانی Statistics را نمایش می دهد.
- تعداد سطرحای شرکت کننده در stats را نمایش می دهد.
- اطلاعاتی درباره Filtered Statistics نمایش می دهد.
2- Density Vector چیست؟
- Density Vector به معنی بردار چگالی است و ارتباط مابین ستون ها را اندازه گیری می کند.
- Density Vector به هیچ عنوان توسط Query Optimizer استفاده نمی شود.
با استفاده از Density Vector می توان میزان Selectivity را محاسبه نمود.
فرمول محاسبه Dencity:
تعداد مقادیر غیرتکراری فیلد / 1
عدد بدست آمده از فرمول بالا هر چه به عدد 1 نزدیک تر باشد Selectivity کاهش خواهد یافت و برعکس هر چه به صفر نزدیک تر باشد Selectivity افزایش خواهد یافت.
3- Histogram چیست؟
- Histogram صرفاً جدولی است برای نگهداری آمار مقادیر مختلف
- در جدول Histogram داده ها به شکل Step یا Range Value ذخیره می شود.
- در جدول Histogram حداکثر 200 Step یا Bucket می توان ذخیره نمود.
در ادامه بحث Statistics خواهید دید ...!
با خرید جلسه 6 از بسته آموزشی "افزایش کارایی پایگاه داده" موارد زیر را خواهید دید:
- چگونه اجزاء مختلف یک Stats را مشاهده کنم؟
- با توجه به محدودیت 200 Step در Histogram، نحوه ی ایجاد Stats برای جداولی که شامل میلیون ها رکورد هستند چگونه است.
دسترسی به موارد آموزشی بالا در بسته خریداری شده
- شماره جلسه: 6
- نام فایل ویدئو: 03
- فرمت فایل: mp4.
نقطه شروع بحث بالا (Statistics) در ویدئو: 20:23

