

در این مقاله به آموزش import کردن اعداد و رشته های مخلوط شده در متلب می پردازیم.
ما همیشه با اعداد سروکار نداریم. برخی مواقع نیاز داریم تا با اعداد و رشته های مخلوط شده، کار کنیم. اما تنها تعدادی از تابع های مخصوص import کردن، با اعداد و رشته(های مخلوط شده) کار می کنند.
دو تا از این تابع ها که معمولا در این زمینه مورد استفاده قرار می گیرند، عبارتند از:
- تابع ()textscan
- تابع ()readtable
هر یک از این توابع، قابلیت های مخصوص به خودش را دارد.
از تابع ()readtable برای کار کردن با خروجی پایگاه های داده استفاده می شود. فایل های خروجی پایگاه های داده، معمولا دارای عنوان(برای ستون ها) هستند.
بعنوان مثال، در داده های خروجی زیر، عنوان سطر ها و ستون ها مشخص شده اند. همان طور که در تصویر زیر مشاهده می کنید، هر ستون یک نام دارد، و هر سطر هم با یک ID مشخص شده است. برای دانلود این فایل csv اینجا کلیک کنید.

تابع ()readtable خصوصیت های فراوانی دارد، که در زیر به آنها اشاره می کنیم:
- خصوصیت FileType: نوع فایل مورد نظر را مشخص می کند. و مقادیر text و spreadsheet را می پذیرد.
- خصوصیت ReadVariableNames: اگر مقدار false را برای آن در نظر بگیریم، ردیف اول داده های ورودی را بعنوان نام ستون ها در نظر نمی گیرد. مقدار پیش فرض آن، true می باشد. همچنین می توان مقادیر 0 و 1 را برای آن در نظر گرفت.
- خصوصیت ReadRowNames: تعیین می کند که آیا داده های اولین ستون بعنوان نام سطرها در نظر گرفته شود یا نه. دو مقدار true و false (یا 0 و 1) را می توان برای آن در نظر گرفت. مقدار false پیش فرض است.
- خصوصیت TreatAsEmpty
- خصوصیت Delimiter: تعیین می کند که از چه کاراکتری در فایل مورد نظر بعنوان جداکننده، استفاده شده است.
- خصوصیت HeaderLines: تعداد خط هایی که می خواهیم در ابتدای فایل، نادیده گرفته شوند را تعیین می کند. می تواند مقدار 0(پیش فرض) یا هر عدد صحیح مثبت دیگری را بپذیرد.
- خصوصیت Format: این خصوصیت با استفاده از یک یا چند مبدل، هر یک از ستون ها را فرمت می کند. حالت پیش فرض برای این خصوصیت این است که برای داده های عددی از نوع داده ی double استفاده کند. مگر اینکه ستون مورد نظر حاوی داده های غیر عددی باشد، که در این صورت تمامی داده ها بصورت یک رشته نشان داده می شوند. اما شما می توانید با استفاده از مبدل d% به جای نوع داده ی double از نوع داده ی int32 استفاده کنید. برای مشاهده ی جزئیات مبدل های فیلتر، اینجا کلیک کنید.
- خصوصیت Sheet
- خصوصیت Range
- خصوصیت Basic: تعیین می کند که آیا تابع ()readtable داده های منبع را در حالت Basic بخواند یا نه.
برای اینکه تاثیر تابع ()readtable را بر روی فایل MixedData.csv در عمل مشاهده کنید، دستور زیر را در متلب تایپ کنید و سپس کلید Enter را فشار دهید:
دستور:
MixedData = readtable('MixedData.csv', 'ReadRowNames', true, 'Format', '%d%s%d%s')خروجی زیر را مشاهده خواهید نمود:
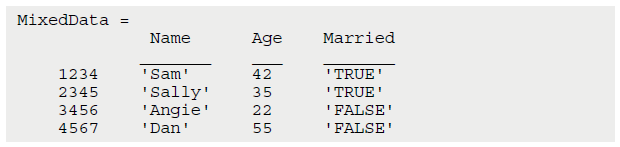
همان طور که مشاهده می کنید، ستون ها دارای نام های مناسبی هستند و به هر ردیف هم یک شناسه تعلق گرفته است. تنها چیزی که از این جدول حذف شده است، کلمه ی ID است. این کلمه، نام ستون شناسه ها بوده است که هیچ نیازی به آن نمی باشد.
در دستوری که آن را اجرا کردیم، دو خصوصیت و دو مقدار برای آنها مشخص نمودیم. اولین خصوصیتی که مشخص کردیم، خصوصیت ReadRowNames بود. که مقدار آن را برابر با true قرار دادیم. این مقداز از تابع ()readtable می خواهد که اولین ستون از هر سطر را بعنوان یک شناسه در نظر بگیرد نه بعنوان داده.
دومین خصوصیتی که مشخص کردیم، خصوصیت Format بود که مقدار آن را برابر با d%s%d%s% قرار دادیم. d% مشخص کننده ی int32 است. و s% مشخص کننده ی رشته یا همان string است. هریک از این چهار خاصیت، به ترتیب بر روی هریک از ستون ها اعمال می شوند.
این جدول به دست آمده، ویژگی های جالبی دارد. بعنوان مثال اگر عبارت ('MixedData('1234','Age را تایپ کنید و سپس کلید Enter را فشار دهید، خروجی زیر را مشاهده خواهید نمود:

همان طور که مشاهده می کنید، در خروجی، یک جدول به دست آورده ایم به طوری که در آن، مقدار دلخواه ما برگردانده شده است. به کاربرد پرانتزها دقت کنید.
برای اینکه بتوانید به جای یک جدول، یک داده ی حقیقی را به دست بیاورید، دستور زیر را در متلب تایپ کنید و سپس کلید Enter را فشار دهید:
دستور:
MixedData{'1234', 'Age'}با اجرای دستور بالا، مقدار 42 را به دست خواهید آورد.
همان طور که در دستور بالا مشاهده می کنید، از آکولادها استفاده کرده ایم. استفاده از آکولادها یعنی می خواهیم در خروجی به جای یک جدول، یک مقدار را به دست بیاوریم. هنوز هم می توانید از اندیس ها برای به دست آوردن داده ی خود استفاده کنید. بعنوان مثال دستور زیر را در متلب تایپ کنید و سپس کلید Enter را فشار دهید:
دستور:
MixedData{1,2}دوباره همان مقدار 42 را به دست خواهید اورد.
اگر متغیر MixedData را در متلب باز کنیم، مشاهده می کنیم که متلب از دو نوع شناسه گذاری برای سطرها و ستون ها استفاده کرده است. به عکس زیر توجه کنید:
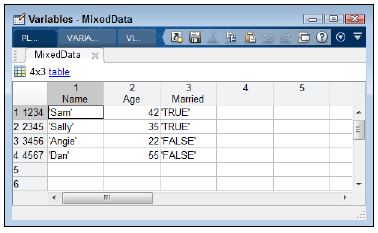
معمولا تابع ()readtable تمام داده های عددی را از نوع double تلقی می کند. اما در دستورات بالا، با استفاده از خصوصیت Format تعیین کردیم که یک مقدار صحیح(integer) به جای آن به ما داده شود. بعنوان مثال دستور زیر را در متلب تایپ کنید و سپس کلید Enter را فشار دهید:
دستور:
class(MixedData{'1234','Age'})خواهید دید که در خروجی مقدار int32 نشان داده می شود. بنابراین خروجی ما یک عدد صحیح است.
تعریف انواع جداکننده ها(delimiter)
همه ی نرم افزارها از یک جداکننده ی یکسان استفاده نمی کنند. و اگر هیچ کس قواعد import کردن را نپذیرد، انجام این کار بسیار سخت خواهد بود.
مثالی که در این بخش می خواهیم از آن استفاده کنیم، از قواعد import کردن پیروی نمی کند. نام این فایل، Delimiters.csv است و می توانید برای دانلود آن، اینجا کلیک کنید. محتویات این فایل به صورت زیر است:
ID;Name;Age;Married
1234;"Sam";42;TRUE
2345;"Sally";35;TRUE
3456;"Angie";22;FALSE
4567;"Dan";55;FALSEبرای اینکه ببینید خواندن این فایل چقدر بدجور است، دستور زیر را در متلب تایپ کنید و کلید Enter را فشار دهید:
دستور
MixedData = readtable('Delimiters.csv','ReadRowNames', true) خروجی به صورت زیر خواهد بود:

خروجی بالا نشان می دهد که متلب قادر نیست محتویات این فایل را بخواند، زیرا این فایل حاوی چندین نوع داده می باشد. ممکن است شما بتوانید به راحتی فایل مورد نظر را بخوانید اما متلب نیاز به کمک دارد. بنابراین باید جداکننده یا همان delimiter را برای متلب تعیین کنیم. یعنی مشخص کنیم که این داده ها با چه نمادی از یکدیگر جدا شده اند. بنابراین دستور زیر را در متلب وارد کنید و کلید Enter را فشار دهید:
دستور
MixedData = readtable('Delimiters.csv', 'ReadRowNames', true, 'Delimiter', ';')خروجی دستور بالا به صورت زیر خواهد بود:
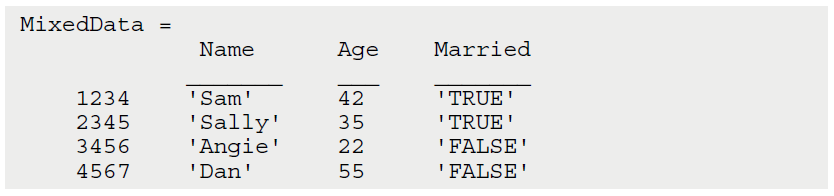
همان طور که مشاهده می کنید، خروجی دلخواه ما به دست آمد. اگر دقت کرده باشید، می بینید که به دور نام ها(name) علامت های دبل-کوتیشن وجود ندارند. زیرا در این مورد، متلب دبل-کوتیشن ها را حذف کرده است. اگر به جای s% از q% استفاده کنیم، به متلب می گوییم که در خروجی، دبل-کوتیشن ها را حذف کن.
اگر در این مثال، به جای دبل-کوتیشن ها از تک کوتیشن به دور نام ها استفاده شده بود، می توانستید از تابع ()textread برای حذف آنها استفاده کنید.
import کردن بخشی از سطرها یا ستون ها در متلب
گاهی اوقات به تمام اطلاعات یک فایل نیاز نداریم و تنها به بعضی از سطرها و ستون های آن نیاز داریم. تمامی چهار تابعی که در این فصل مورد استفاده قرار دادیم، قابلیت هایی در زمینه ی انتخاب سطرها و ستون ها ارائه می دهند، اما در اینجا قصد داریم از تابع ()csvread استفاده کنیم. برای اینکه محدوده ای از داده ها به شما نشان داده شود، دستور زیر را در متلب تایپ کنید و کلید Enter را فشار دهید:
دستور
CSVOutput = csvread('NumericData.csv', 0, 0, [0, 0, 1, 1] )خروجی به صورت زیر خواهد بود:

اولین آرگومان از تابع ()csvread نام فایلی است که می خواهیم آن را بخوانیم. آرگومان های دوم و سوم نیز مشخص کننده ی سطر و ستونی هستند که می خواهیم خواندن اطلاعات از آنجا شروع شود. در این مثال، خواندن فایل از سطر 0 و ستون 0 آغاز می شود.
آرگومان چهارم، یک ماتریس است که محدوده ی مقادیری که می خواهیم خوانده شوند را مشخص می کند. بنابراین ابتدا ما با استفاده از آرگومان دوم و سوم دستور بالا، نقطه ای که می خواهیم داده ها از آنجا خوانده شوند را مشخص می کنیم و سپس با استفاده از یک ماتریس(یعنی همان آرگومان چهارم) در این محدوده ی باقی مانده، دو نقطه را مشخص می کنیم تا داده های بین آنها و خود آن نقاط خوانده شوند. نقطه ی اول، نقطه ی شروع و نقطه ی دوم، نقطه ی پایان را مشخص می کند.
برای اینکه این موضوع را بهتر متوجه شوید،ابتدا این فایل را دانلود کنید و سپس دستور زیر را در متلب تایپ کنید و کلید Enterرا فشار دهید:
دستور:
CSVOutput = csvread('NumericData.csv', 0, 1, [0, 1, 2, 2])حالا همان طور که در زیر مشاهده می کنید، داده های زیر از فایل NumericData.csv برگردانده می شوند:
داده های آبی رنگ از فایل NumericData.csv برگردانده می شوند:
15,25,30
18,29,33
21,35,41
خروجی اصلی به صورت زیر خواهد بود: 
نکته: اندیس سطرها و ستون ها در هنگام استفاده از تابع ()csvread از 0 شروع می شوند. این یعنی سطر اول 0 است و ستون اول نیز 0 است. در یک جدول سه سطری، سطرها از 0 تا 2 نما گذاری می شوند نه از 1 تا 3. به همین صورت، در یک جدول سه ستونه، ستون ها از 0 تا 2 نام گذاری می شوند نه از 1 تا 3.

